Набор данных LeRobot
LeRobot — это открытая платформа для стандартизации данных обучения роботов от Hugging Face, специально разработанная для сценариев обучения роботов и обучения с подкреплением. Она предоставляет единую спецификацию формата данных, позволяя исследователям легче обмениваться, сравнивать и воспроизводить эксперименты по обучению роботов, значительно снижая затраты на преобразование форматов данных между различными исследовательскими проектами.
Экспорт данных
Платформа EmbodyFlow полностью поддерживает экспорт данных в стандартном формате LeRobot, которые можно напрямую использовать в процессе обучения моделей VLA (Vision-Language-Action). Экспортируемые данные содержат полную мультимодальную информацию об операциях робота: данные визуального восприятия, инструкции на естественном языке и соответствующие последовательности действий, формируя полный цикл отображения данных «восприятие-понимание-исполнение».
Экспорт данных в формате LeRobot требует высоких вычислительных ресурсов. Бесплатная версия платформы данных EmbodyFlow имеет разумные ограничения на количество экспортов для каждого пользователя, в то время как платная версия предлагает неограниченные услуги экспорта и оснащена ускорением GPU, что может значительно повысить скорость обработки экспорта.
1. Выбор данных для экспорта
Перед экспортом данных необходимо завершить работу по разметке. Процесс разметки устанавливает точное соответствие между последовательностями действий робота и соответствующими инструкциями на естественном языке, что является необходимым условием для обучения моделей VLA. Благодаря этому сопоставлению модель учится понимать языковые команды и преобразовывать их в точные управляющие действия робота.
Подробный процесс разметки данных и советы по пакетной разметке см. в: Руководство по разметке данных
После завершения разметки вы можете просмотреть все размеченные наборы данных в интерфейсе экспорта. Система поддерживает гибкий выбор подмножеств данных, позволяя выбирать конкретные данные для экспорта в соответствии с вашими потребностями.
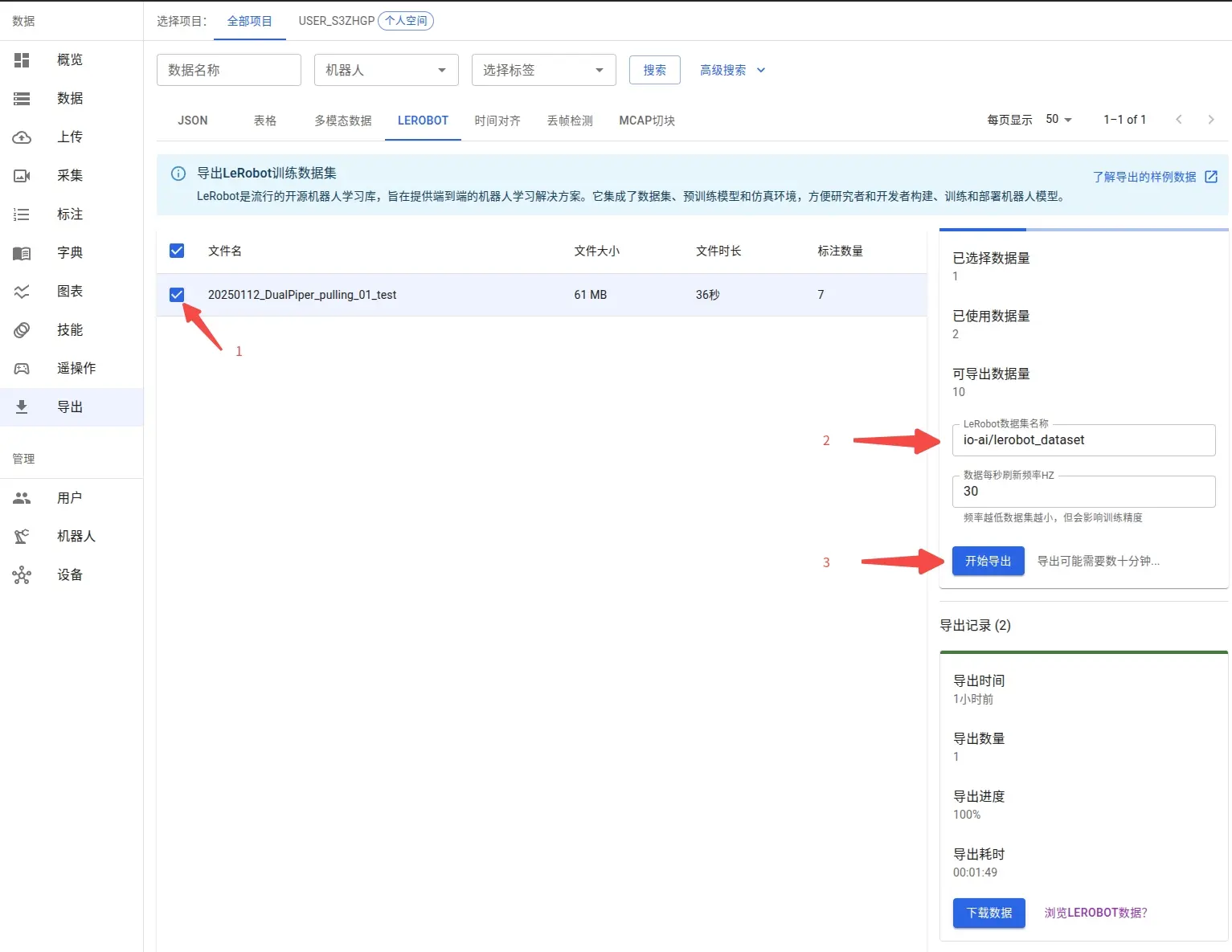
Поддерживается пользовательская настройка именования наборов данных. Если вы планируете опубликовать набор данных на платформе Hugging Face, рекомендуется использовать стандартный формат именования репозитория (например, myproject/myrepo1), что облегчит последующий обмен моделями и совместную работу.
Параметры конфигурации экспорта
На панели конфигурации в правой части интерфейса экспорта можно задать следующие параметры экспорта:
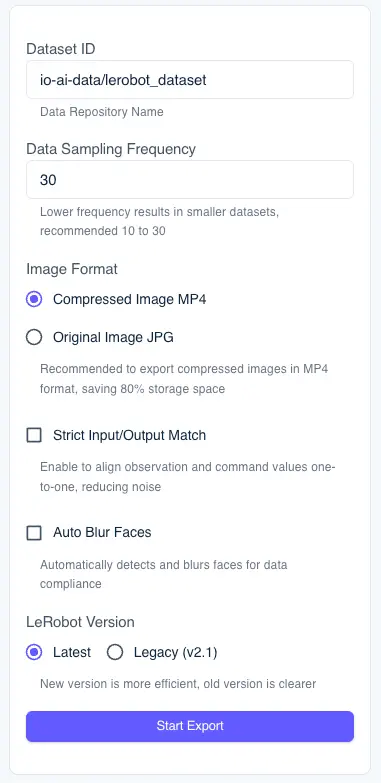
Частота дискретизации данных: Управляет частотой дискретизации данных (рекомендуется 10-30 Гц). Чем ниже частота, тем меньше объем создаваемого набора данных, но часть детальной информации может быть потеряна.
Формат изображения:
- MP4 (рекомендуется): Формат сжатого изображения, позволяющий сэкономить около 80% дискового пространства, подходит для экспорта крупномасштабных наборов данных.
- JPG: Исходный формат изображения, сохраняющий полное качество изображения, но имеющий большой объем файла.
Строгое соответствие входу и выходу модели: При включении система автоматически обрезает значения наблюдений и инструкций, обеспечивая соответствие «один к одному», что помогает уменьшить шумовые помехи и повысить качество обучающих данных.
Автоматическое размытие лиц: При включении система автоматически идентифицирует лица в кадрах и выполняет их размытие. Эта функция помогает:
- Защитить личную конфиденциальность и соответствовать требованиям нормативного соответствия данных.
- Подходит для наборов данных, содержащих кадры с операторами.
- Автоматически обрабатывать информацию о лицах во всех экспортируемых изображениях.
Чем больше объем данных, тем больше времени занимает экспорт. Рекомендуется выполнять экспорт по типам задач, избегая одновременной обработки всех данных. Пакетный экспорт не только повышает скорость обработки, но и облегчает последующее управление данными, контроль версий и целевое обучение моделей.
2. Скачивание и распаковка файлов экспорта
Время, затрачиваемое на процесс экспорта, зависит от масштаба данных и текущей нагрузки системы, обычно оно составляет несколько десятков минут. Страница будет автомати�чески обновлять статус прогресса, вы можете вернуться позже, чтобы проверить результаты обработки.
После завершения экспорта в области История экспорта в правой части страницы появится кнопка Скачать данные. При нажатии вы получите пакет сжатых файлов в формате .tar.gz.

Рекомендуется создать локально специальный каталог (например, ~/Downloads/mylerobot3) для распаковки файлов, чтобы избежать путаницы с другими данными:

Распакованные файлы строго следуют спецификации стандартного формата наборов данных LeRobot, содержат полные мультимодальные данные: данные визуального восприятия, информацию о состоянии робота, метки действий и т. д.:

3. Пользовательское сопоставление топиков (Topic)
При экспорте набора данных LeRobot системе необходимо сопоставить топики (Topic) ROS/ROS2 с полями наблюдений (observation.state) и действий (action) в стандартном формате LeRobot. Понимание правил сопоставления топиков имеет решающее значение для правильного экспорта пользовательских наборов данных.
Правила сопоставления топиков по умолчанию
Платформа EmbodyFlow использует механизм автоматического распознавания на основе суффиксов имен топиков:
Правила сопоставления наблюден�ий (observation.state):
- Если имя топика заканчивается на
/joint_stateили/joint_states, система автоматически распознает значения его полейpositionкак наблюдения и сопоставит их с полемobservation.state. - Например: топики
io_teleop/joint_states,/arm/joint_stateи т. д. будут распознаны как наблюдения.
Правила сопоставления действий (action):
- Если имя топика заканчивается на
/joint_cmdили/joint_command, система автоматически распознает значения его полейpositionкак инструкции действий и сопоставит их с полемaction. - Например: топики
io_teleop/joint_cmd,/arm/joint_commandи т. д. будут распознаны как значения действий.
Чтобы обеспечить корректный экспорт данных, рекомендуется следовать вышеуказанным правилам именования при записи данных. Если в вашей робототехнической системе используется другой стиль именования, вы можете связаться с командой технической поддержки для адаптации.
Поддержка пользовательских топиков
Если вы создали пользовательские топики, имена которых не соответствуют вышеуказанным правилам по умолчанию, вы можете обработать их следующими способами:
-
Переименование топиков: На этапе записи данных переименуйте пользовательские топики в имена, соответствующие правилам по умолчанию (например,
/joint_statesили/joint_command). -
Связь с технической поддержкой: Если изменить имена топиков невозможно, вы можете связаться с командой технической поддержки платформы EmbodyFlow. Мы выполним адаптацию в соответствии с вашим конкретным стилем именования, чтобы обеспечить корректное сопоставление данных с форматом LeRobot.
Текущая версия временно не поддерживает прямое указание пользовательского сопоставления топиков в интерфейсе экспорта. Если у вас есть особые потребности, рекомендуется заранее связаться с командой технической поддержки, и мы выполним соответствующую адаптацию конфигурации перед экспортом.
Визуализация и проверка данных
Чтобы помочь пользователям быстро понять и проверить содержимое данных, LeRobot предоставляет два основных решения для визуализации данных. Каждое решение имеет свои сценарии применения и уникальные преимущества:
| Сценарий использования | Решение для визуализации | Основные преимущества |
|---|---|---|
| Локальная разработка и отладка | Локальный просмотр через Rerun SDK | Полная функциональность, высокая интерактивность, доступность в офлайне |
| Быстрый просмотр и обмен | Онлайн-просмотр через Hugging Face | Не требует установки, легко делиться, доступ в любое время |
1. Локальная визуализация с использованием Rerun SDK
Установив локально репозиторий lerobot, вы можете использовать встроенный в него скрипт lerobot/scripts/visualize_dataset.py совместно с Rerun SDK для реализации интерактивной мультимодальной визуализации данных на временной шкале. Этот способ позволяет одновременно отображать изображения, состояния, действия и другую многомерную информацию, предоставляя богатейшие функции взаимодействия и возможности настройки.
Подготовка среды и установка зависимостей
Убедитесь, что ваша версия Python — 3.10 или выше, затем выполните следующие команды установки:
# Установка Rerun SDK
python3 -m pip install rerun-sdk==0.23.1
# Клонирование официального репозитория LeRobot
git clone https://github.com/huggingface/lerobot.git
cd lerobot
# Установка среды разработки LeRobot
pip install -e .
Запуск визуализации данных
python3 -m lerobot.scripts.visualize_dataset \
--repo-id io-ai-data/lerobot_dataset \
--root ~/Downloads/mylerobot3 \
--episode-index 0
Описание параметров:
--repo-id: Идентификатор набора данных Hugging Face (например,io-ai-data/lerobot_dataset).--root: Локальный путь хранения набора данных LeRobot, указывающий на распакованный каталог.--episode-index: Указывает индекс эпизода для визуализации (отсчет начинается с 0).
Генерация файлов для офлайн-визуализации
Вы можете сохранить результаты визуализации в виде файлов формата Rerun (.rrd) для удобного просмотра в офлайне или обмена с членами команды:
python3 -m lerobot.scripts.visualize_dataset \
--repo-id io-ai-data/lerobot_dataset \
--root ~/Downloads/mylerobot3 \
--episode-index 0 \
--save 1 \
--output-dir ./rrd_out
# Офлайн-просмотр сохраненного файла визуализации
rerun ./rrd_out/lerobot_pusht_episode_0.rrd
Удаленная визуализация (режим WebSocket)
Если необходимо обрабатывать данные на удаленном сервере, но просматривать их локально, можно использовать режим подключения по WebSocket:
# Запуск службы визуализации на стороне сервера
python3 -m lerobot.scripts.visualize_dataset \
--repo-id io-ai-data/lerobot_dataset \
--root ~/Downloads/mylerobot3 \
--episode-index 0 \
--mode distant \
--ws-port 9091
# Подключение к удаленной службе визуализации локально
rerun ws://IP-АДРЕС_СЕРВЕРА:9091
2. Онлайн-визуализация с использованием Hugging Face Spaces
Если вы не хотите устанавливать локальную среду, LeRobot предоставляет онлайн-инструмент визуализации на базе Hugging Face Spaces, который можно использовать без каких-либо локальных зависимостей. Этот способ особенно подходит для быстрого предварительного просмотра данных или обмена содержимым набора данных с командой.
Функция онлайн-визуализации требует загрузки данных в онлайн-репозиторий Hugging Face. Следует отметить, что бесплатные учетные записи Hugging Face поддерживают визуализацию только публичных репозиториев, что означает, что ваши данные будут в открытом доступе. Если данные содержат конфиденциальную информацию и должны оставаться частными, рекомендуется использовать локальное решение для визуализации.
Порядок действий
- Перейдите к онлайн-инструменту визуализации: https://huggingface.co/spaces/lerobot/visualize_dataset
- В поле Dataset Repo ID введите идентификатор вашего набора данных (например,
io-intelligence/piper_uncap_pen). - На левой панели выберите номер эпизода для просмотра (например,
Episode 0). - В верхней части страницы предоставлено несколько вариантов воспроизведения, вы можете выбрать наиболее подходящий способ просмотра.
Руководство по обучению моделей
Обучение моделей на основе набора данных LeRobot является ключевым звеном в реализации обучения роботов. Различные архитектуры моделей предъявляют разные требования к параметрам обучения и предобработке данных. Выбор правильной стратегии модели имеет решающее значение для результатов обучения.
Стратегия выбора модели
Текущие основные модели VLA включают:
| Тип модели | Сценарий применения | Основные особенности | Рекомендуемое использование |
|---|---|---|---|
| smolVLA | Однокартовая среда, быстрое прототипирование | Умеренное количество параметров, эффективное обучение | Потребительские GPU, доказательство концепции |
| Pi0 / Pi0.5 | Сложные задачи, мультимодальное слияние | Ведущие модели VLA, мощная спос�обность к обобщению | Производственные среды, сложное взаимодействие роботов |
| ACT | Оптимизация для одной задачи | Высокая точность предсказания действий | Конкретные задачи, высокочастотное управление |
| Diffusion | Генерация плавных действий | На основе диффузионных моделей, высокое качество траекторий | Задачи, требующие плавных траекторий |
| VQ-BeT | Дискретизация действий | Векторное квантование, быстрый инференс | Сценарии управления в реальном времени |
| TDMPC | Управление с предсказанием модели | Высокая эффективность выборки, онлайн-обучение | Сценарии с дефицитом данных |
Для дообучения моделей Pi0/Pi0.5 необходимо использовать фреймворк OpenPI. Хотя данные экспортируются в формате LeRobot v2.1, процесс обучения отличается от LeRobot CLI.
Подробное руководство по дообучению см. в: Руководство по дообучению моделей Pi0 и Pi0.5
Подробности обучения smolVLA (рекомендуется для начинающих)
smolVLA — это модель VLA, оптимизированная для потребительских/однокартовых сред. Вместо обучения с нуля настоятельно рекомендуется выполнять дообучение (fine-tuning) на основе официальных предобученных весов, что может значительно сократить время обучения и улучшить конечный результат.
Команды обучения LeRobot используют следующий формат параметров:
- Тип стратегии:
--policy.type smolvla(указывает, какую модель использовать). - Значения параметров: разделяются пробелами, например,
--batch_size 64(не--batch_size=64). - Логические значения: используйте
true/false, например,--save_checkpoint true. - Список значений: разделяется пробелами, например,
--policy.down_dims 512 1024 2048. - Загрузка модели: по умолчанию необходимо добавить
--policy.push_to_hub false, чтобы отключить автоматическую загрузку на Hugging Face Hub.
Подготовка среды
# Клонирование репозитория LeRobot
git clone https://github.com/huggingface/lerobot.git
cd lerobot
# Установка полной среды с поддержкой smolVLA
pip install -e ".[smolvla]"
Дообучение (рекомендуемое решение)
- По умолчанию рекомендуется использовать локальный набор данных: обучающие данные обычно имеют большой объем, рекомендуется напрямую использовать локальный распакованный каталог.
--dataset.repo_id local/xxx--dataset.root /path/to/dataset(каталог должен содержатьmeta.json,data/и т. д.).
- Если вы уже загрузили данные на Hugging Face Hub: можно оставить только
--dataset.repo_id your-name/your-repoи удалить--dataset.root.
Пример дообучения на локальном наборе данных (рекомендуется по умолчанию)
# Пример: ваши данные находятся в локальном каталоге (содержащем meta.json, data/ и т. д.)
DATASET_ROOT=~/Downloads/mylerobot3
lerobot-train \
--policy.type smolvla \
--policy.pretrained_path lerobot/smolvla_base \
--dataset.repo_id local/mylerobot3 \
--dataset.root ${DATASET_ROOT} \
--output_dir /data/lerobot_smolvla_finetune \
--batch_size 64 \
--steps 20000 \
--policy.optimizer_lr 1e-4 \
--policy.device cuda \
--policy.push_to_hub false \
--save_checkpoint true \
--save_freq 5000
Практические советы:
- Подготовка данных: рекомендуется записать 50+ фрагментов демонстрации задач, чтобы обеспечить охват различных положений объектов, поз и изменений окружающей среды.
- Ресурсы для обучения: обучение на 20к ш�агов на одной видеокарте A100 занимает около 4 часов; на потребительских видеокартах можно уменьшить
batch_sizeили включить накопление градиента. - Настройка гиперпараметров: начинайте дообучение с
batch_size=64,num_train_steps=20kи скорости обучения1e-4. - Когда стоит обучаться с нуля: рассматривайте обучение с нуля с использованием
--policy.type=smolvlaтолько при наличии огромного набора данных (тысячи часов).
Обучение с нуля (для опытных пользователей)
# Обучение с нуля (пример локального набора данных)
DATASET_ROOT=~/Downloads/mylerobot3
lerobot-train \
--policy.type smolvla \
--dataset.repo_id local/mylerobot3 \
--dataset.root ${DATASET_ROOT} \
--output_dir /data/lerobot_smolvla_fromscratch \
--batch_size 64 \
--steps 200000 \
--policy.optimizer_lr 1e-4 \
--policy.device cuda \
--policy.push_to_hub false \
--save_checkpoint true \
--save_freq 10000
Советы по оптимизации производительности
Оптимизация видеопамяти:
# Добавьте следующие параметры для оптимизации использования видеопамяти
--policy.use_amp true \
--num_workers 2 \
--batch_size 32 # Уменьшите размер пакета
Мониторинг обучения:
- Настройте Weights & Biases (W&B) для мониторинга кривых обучения и метрик оценки.
- Установите разумные интервалы валидации и стратегии ранней остановки.
- Регулярно сохраняйте контрольные точки на случай прерывания обучения.
Руководство по обучению модели ACT
ACT (Action Chunking Transformer) разработан для обучения стратегиям в рамках одной задачи или коротких последовательностей. Хотя он уступает smolVLA в мультизадачном обобщении, ACT остается экономически эффективным выбором в сценариях с четко определенными задачами, высокой частотой управления и относительно короткими последовательностями.
Модель ACT требует, чтобы policy.n_action_steps ≤ policy.chunk_size. Рекомендуется установить оба параметра на одинаковое значение (например, 100), чтобы избежать ошибок конфигурации.
Требования к предобработке данных
Обработка траекторий:
- Обеспечьте одинаковую длину фрагментов и выравнивание по времени (рекомендуются фрагменты действий по 10-20 шагов).
- Выполните нормализацию данных действий, приведя их к единому масштабу и единицам измерения.
- Поддерживайте согласованность данных наблюдений, особенно внутренних параметров камер и ракурсов.
Конфигурация обучения:
Пример обучения на локальном наборе данных (рекомендуется по умолчанию)
DATASET_ROOT=~/Downloads/mylerobot3
lerobot-train \
--policy.type act \
--dataset.repo_id local/mylerobot3 \
--dataset.root ${DATASET_ROOT} \
--output_dir /data/lerobot_act_finetune \
--batch_size 8 \
--steps 100000 \
--policy.chunk_size 100 \
--policy.n_action_steps 100 \
--policy.n_obs_steps 1 \
--policy.optimizer_lr 1e-5 \
--policy.device cuda \
--policy.push_to_hub false \
--save_checkpoint true \
--save_freq 10000
Рекомендации по настройке гиперпараметров:
- Размер пакета: начинайте с 8, корректируйте в зависимости от видеопамяти (ACT рекомендует небольшие пакеты).
- Скорость обучения: рекомендуется 1e-5, ACT чувствителен к скорости обучения.
- Количество шагов обучения: 100к-200к шагов в зависимости от сложнос�ти задачи.
- Размер блока действий: рекомендуется установить chunk_size и n_action_steps равными 100.
- Регуляризация: при возникновении переобучения увеличьте разнообразие данных или используйте раннюю остановку.
Стратегии настройки производительности
Борьба с переобучением:
- Увеличьте разнообразие собираемых данных.
- Применяйте соответствующие методы регуляризации.
- Используйте стратегии ранней остановки.
Борьба с недообучением:
- Увеличьте количество шагов обучения.
- Отрегулируйте график изменения скорости обучения.
- Проверьте качество и согласованность данных.
Часто задаваемые вопросы (FAQ)
Вопросы по экспорту данных
В: Сколько времени занимает экспорт данных LeRobot?
О: Время экспорта в основном зависит от объема данных и текущей нагрузки системы. Обычно на обработку 1 ГБ данных требуется 3-5 минут. Для повышения эффективности рекомендуется выполнять экспорт партиями по типам задач, избегая одновременной обработки слишком больших наборов данных.
В: Какие ограничения на экспорт есть в бесплатной версии?
О: Бесплатная версия имеет разумные ограничения на количество и частоту экспорта для каждого пользователя, конкретные лимиты отображаются в интерфейсе экспорта. Если вам требуется масштабный экспорт данных, рекомендуется перейти на платную версию, чтобы пользоваться неограниченным экспортом и ускорением на GPU.
В: Как проверить целостность экспортированных данных?
О: Используйте встроенный инструмент валидации LeRobot:
python -m lerobot.scripts.validate_dataset --root /path/to/dataset
В: Что делать, если экспортированный набор данных слишком велик?
О: Можно оптимизировать его следующими способами:
- Снизить частоту экспорта (по умолчанию 30fps можно снизить до 10-15fps).
- Разделить экспорт по временным интервалам или типам задач.
- Сжать качество изображений (при условии сохранения эффективности обучения).
Вопросы по визуализации данных
В: Что делать, если установка Rerun SDK завершилась ошибкой?
О: Пожалуйста, проверьте следующие условия:
- Убедитесь, что версия Python ≥ 3.10.
- Проверьте стабильность сетевого соединения.
- Попробуйте установить в виртуальной среде:
python -m venv rerun_env && source rerun_env/bin/activate. - Используйте зеркала (например, TUNA):
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple rerun-sdk==0.23.1.
В: Обязательно ли данные должны быть публичными для онлайн-визуализации?
О: Да. Инструмент онлайн-визуализации в Hugging Face Spaces может обращаться только к публичным наборам данных. Если ваши данные содержат конфиденциальную информацию или должны оставаться частными, используйте локальное решение на базе Rerun SDK.
В: Как загрузить данные на Hugging Face?
О: Используйте официальный инструмент командной строки (CLI):
# Установка Hugging Face CLI
pip install -U huggingface_hub
# Вход в учетную запись
huggingface-cli login
# (Опционально) Создание репозитория набора данных
huggingface-cli repo create your-username/dataset-name --type dataset
# Загрузка набора данных (укажите тип репозитория dataset)
huggingface-cli upload your-username/dataset-name /path/to/dataset --repo-type dataset --path-in-repo .
Вопросы по обучению моделей
В: Какие типы моделей поддерживаются?
О: Формат LeRobot поддерживает несколько основных моделей VLA:
- smolVLA: подходит для однокартовых сред и быстрого прототипирования.
- Pi0: мощные мультимодальные возможности, подходит для сложных задач (относится к фреймворку OpenPI).
- ACT: фокусируется на оптимизации для одной задачи, высокая точность предсказания действий.
Информацию о конкретных поддерживаемых моделях см. здесь: https://github.com/huggingface/lerobot/tree/main/src/lerobot/policies
В: Что делать, если во время обучения не хватает видеопамяти (OOM)?
О: Попробуйте следующие стратегии оптимизации:
- Уменьшить размер пакета:
--batch_size 1или меньше. - Включить обучение со смешанной точностью:
--policy.use_amp true. - Уменьшить количество потоков загрузки данных:
--num_workers 1. - Уменьшить количество шагов наблюдения:
--policy.n_obs_steps 1. - Очистить кэш GPU: добавьте
torch.cuda.empty_cache()в скрипт обучения.
В: Как выбрать подходящую модель?
О: Выбирайте в соответствии с вашими конкретными потребностями:
- Быстрое прототипирование: выберите smolVLA.
- Сложные мультимодальные задачи: выбери�те Pi0 (требуется фреймворк OpenPI).
- Среды с ограниченными ресурсами: выберите smolVLA или ACT.
- Одна специализированная задача: выберите ACT.
В: Как оценивается эффективность обучения?
О: LeRobot предоставляет несколько методов оценки:
- Количественные метрики: ошибка действий (MAE/MSE), сходство траекторий (DTW).
- Качественная оценка: процент успеха тестов на реальном роботе, анализ поведения.
- Оценка на платформе: платформа EmbodyFlow предоставляет визуальные инструменты оценки качества моделей.
В: Сколько примерно времени занимает обучение?
О: Время обучения зависит от нескольких факторов:
- Масштаб данных: 50 демонстрационных фрагментов обычно требуют 2-8 часов.
- Конфигурация оборудования: A100 в 3-5 раз быстрее потребительских видеокарт.
- Выбор модели: smolVLA обучается быстрее, чем ACT.
- Стратегия обучения: дообучение в 5-10 раз быстрее обучения с нуля.
Техническая поддержка
В: Как получить помощь при возникновении технических проблем?
О: Вы можете получить поддержку через следующие каналы:
- Ознакомьтесь с официальной документацией LeRobot: https://huggingface.co/docs/lerobot
- Создайте Issue на GitHub: https://github.com/huggingface/lerobot/issues
- Свяжитесь с командой технической поддержки платформы EmbodyFlow.
- Примите участие в обсуждениях сообщества LeRobot.
В: Поддерживает ли платформа EmbodyFlow автоматическое развертывание моделей?
О: Да, платформа EmbodyFlow поддерживает услуги автоматического развертывания основных моделей, таких как Pi0 (фреймворк OpenPI), smolVLA, ACT и др. Пожалуйста, свяжитесь с командой технической поддержки для получения планов развертывания и информации о ценах.
Связанные ресурсы
Официальные ресурсы
- Домашняя страница проекта LeRobot: https://github.com/huggingface/lerobot
- Коллекция моделей LeRobot: https://huggingface.co/lerobot
- Официальная документация LeRobot: https://huggingface.co/docs/lerobot
- Инструмент онлайн-визуализации Hugging Face: https://huggingface.co/spaces/lerobot/visualize_dataset
Инструменты и фреймворки
- Платформа визуализации Rerun: https://www.rerun.io/
- Hugging Face Hub: https://huggingface.co/docs/huggingface_hub
Академические ресурсы
- Оригинальная статья Pi0: https://arxiv.org/abs/2410.24164
- Статья ACT: Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
- Обзорная статья VLA: Vision-Language-Action Models for Robotic Manipulation
Ресурсы, связанные с OpenPI
- Домашняя страница проекта OpenPI: https://github.com/Physical-Intelligence/openpi
- Physical Intelligence: https://www.physicalintelligence.company/
Ресурсы сообщества
- Обсуждения на GitHub LeRobot: https://github.com/huggingface/lerobot/discussions
- Сообщество обучения роботов Hugging Face: https://huggingface.co/spaces/lerobot
Данный документ будет постоянно обновляться, чтобы отражать последние разработки и лучшие практики в экосистеме LeRobot. Если у вас есть вопросы или предложения, пожалуйста, свяжитесь с нами через каналы технической поддержки платформы EmbodyFlow.