Обучение моделей
Платформа EmbodyFlow предоставляет полные возможности для обучения моделей обучения роботов, поддерживая сквозной рабочий процесс от предварительной обработки данных до развертывания модели. Платформа интегрирует различные основные алгоритмы обучения роботов, обеспечивая эффективную среду обучения для исследователей и разработчиков.
Особенности продукта
Гибкая архитектура
Продукт использует многоуровневую архитектуру для обеспечения масштабируемости системы. Вычислительные мощности для обучения поддерживают несколько вариантов:
- Частное облако: использование GPU-серверов в локальном дата-центре (поддержка параллельного обучения на нескольких картах)
- Публичное облако: аренда вычислительных ресурсов у облачных провайдеров по запросу (оплата по фактическому времени обучения)
От данных к модели
Платформа охватывает всю цепочку данных: от сбора, аннотирования и экспорта до тонкой настройки и развертывания модели.
Поддерживаемые типы моделей
Платформа поддерживает основные модели обучения в области робототехники, охватывая такие направления, как слияние Vision-Language-Action (VLA), имитационное обучение, обучение с подкреплением и другие:
Модели Vision-Language-Action
- SmolVLA - легкая мультимодальная модель, обеспечивающая сквозное обучение инструкциям на естественном языке, визуальному восприятию и действиям робота.
- OpenVLA - крупномасштабная предобученная модель Vision-Language-Action, поддерживающая понимание сложных сцен и планирование операций.
Модели имитационного обучения
- ACT (Action Chunking Transformer) - модель фрагментации действий на базе архитектуры Transformer, разделяющая непрерывные последовательности действий на дискретные блоки для обучения.
- Pi0 / Pi0.5 - флагманские VLA-модели от Physical Intelligence с открытым исходным кодом, настраиваемые через фреймворк OpenPI, обладающие мощными универсальными способностями к манипуляции. Подробнее см. в Руководстве по тонкой настройке Pi0.
- Pi0-Fast - оптимизированная версия алгоритма Pi0, использующая авторегрессионную архитектуру для повышения скорости инференса.
Модели обучения стратегий
- Diffusion Policy - обучение стратегий на основе диффузионных процессов, генерирующее непрерывные траектории действий робота через процесс удаления шума.
- VQBET - Vector Quantized Behavior Transformer, моделирующий дискретизированное пространство действий с использованием Transformer.
Модели обучения с подкреплением
- SAC (Soft Actor-Critic) - алгоритм обучения с подкреплением с максимальной энтропией, балансирующий исследование и эксплуатацию в непрерывных пространствах действий.
- TDMPC - Temporal Difference Model Predictive Control, сочетающий преимущества планирования на основе модели и обучения без модели.
Вышеуказанные модели охватывают основные технические направления и могут применяться в различных задачах робототехники, например:
| Сценарий применения | Используемые модели | Описание |
|---|---|---|
| Уборка стола | SmolVLA, Pi0 | Робот понимает инструкции на естественном языке, такие как «Пожалуйста, убери на столе», и выполняет действия по захвату, перемещению и размещению предметов. |
| Сортировка предметов | ACT | Обучаясь на экспертных демонстрациях сортировки, робот может идентифицировать различные предметы и сортировать их по категориям. |
| Сложные манипуляции | Diffusion Policy | Робот обучается выполнению сложных последовательностей действий, требующих точного управления, таких как сборка или приготовление пищи. |
| Адаптивное управление | Алгоритмы RL, такие как SAC | Робот обучается оптимальным стратегиям управления в динамических средах, адаптируясь к изменениям окружения. |
Рабочий процесс обучения
Платформа предоставляет готовый процесс обучения, не требующий навыков программирования. Весь цикл от подготовки данных до развертывания модели реализуется через веб-интерфейс:
1. Подготовка данных
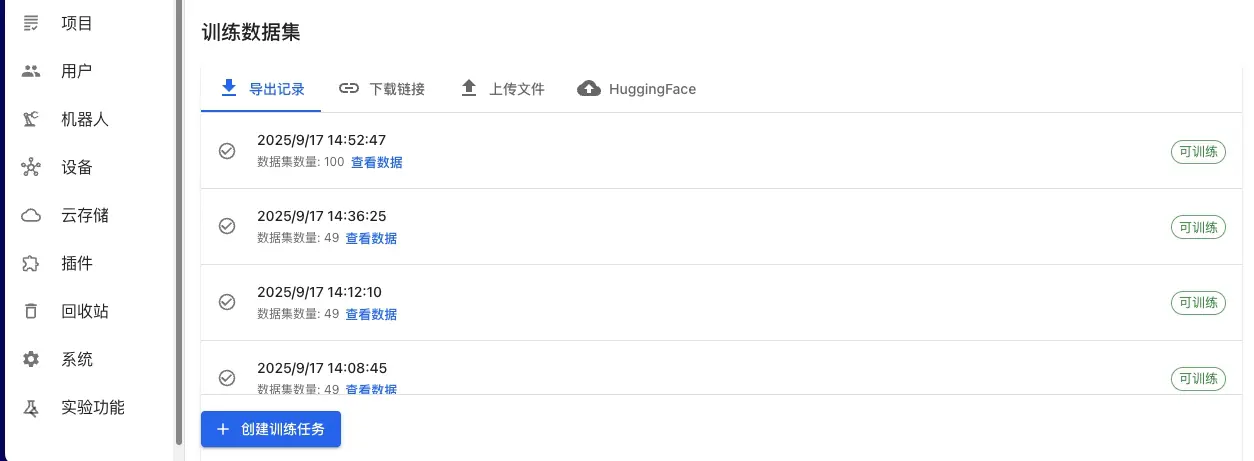
Платформа поддерживает различные источники данных, включая:
- Экспорт данных с платформы - использование демонстрационных данных роботов, аннотированных и экспортированных с платформы.
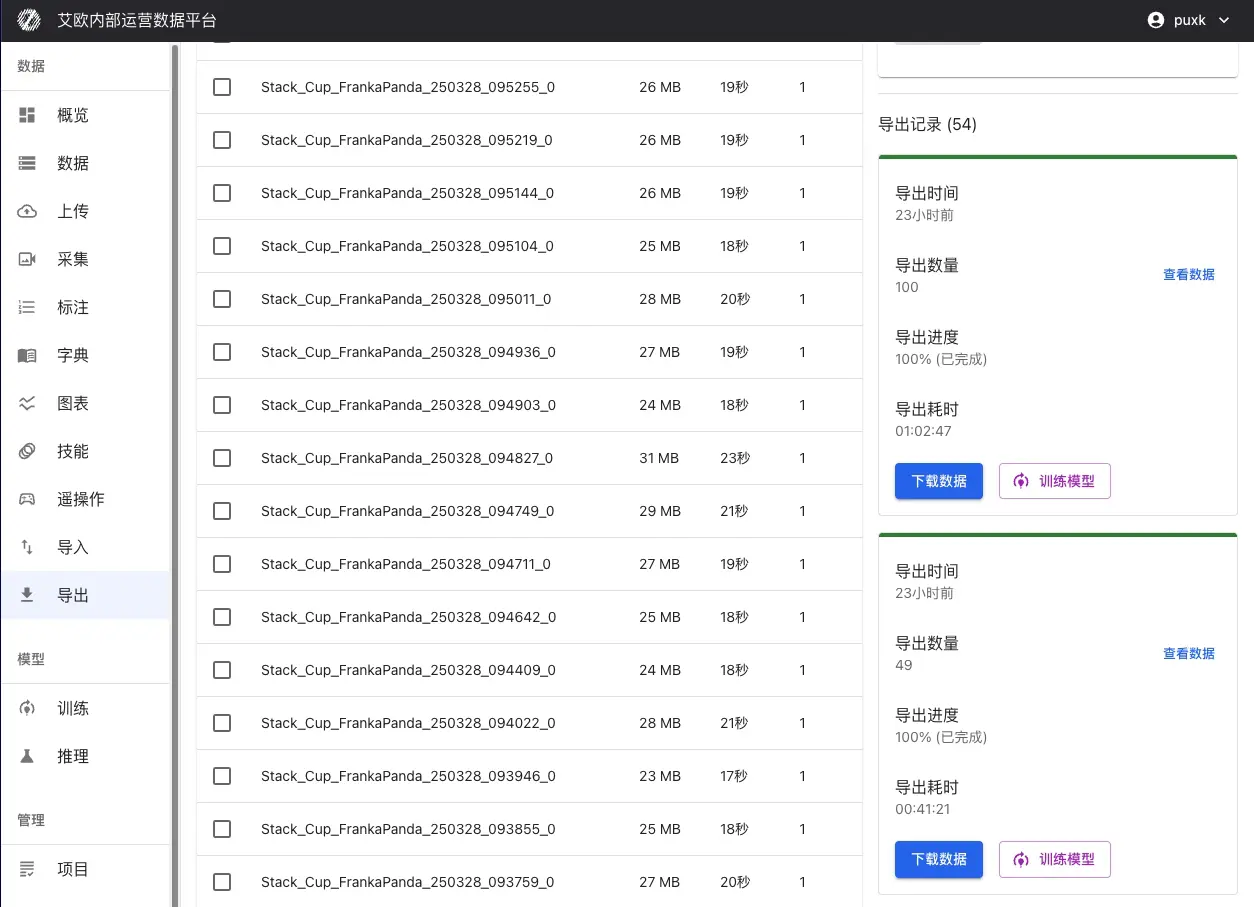
- Внешние наборы данных - импорт общедоступных наборов данных по URL-ссылкам.
- Загрузка локальных данных - поддержка стандартных форматов, таких как HDF5, LeRobot и др.
- Наборы данных HuggingFace - получение открытых данных напрямую из HuggingFace Hub.
2. Конфигурация обучения
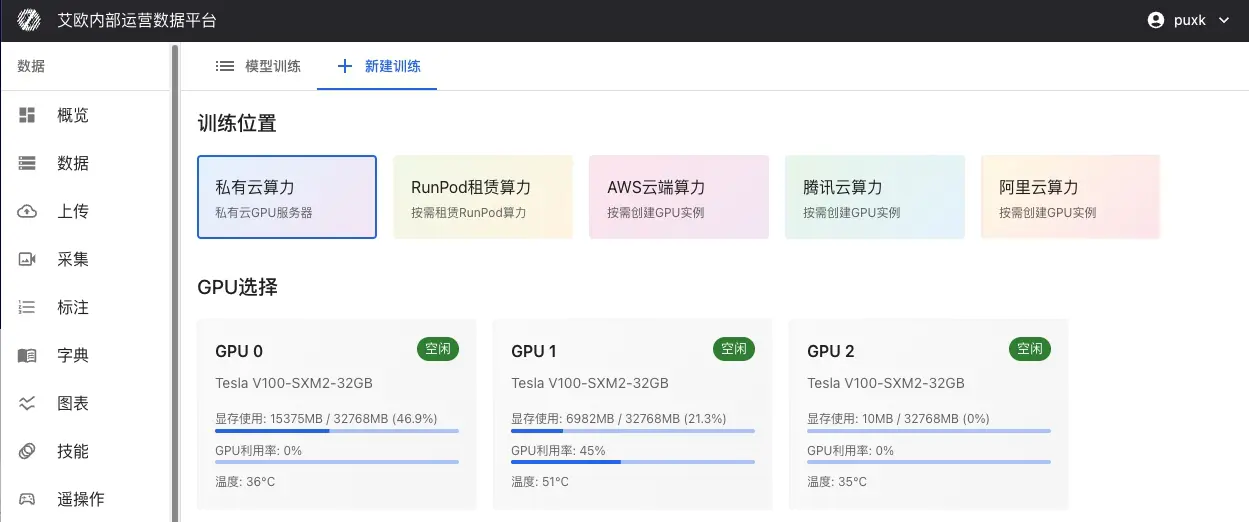
Выбор вычислительных ресурсов
Платформа поддерживает гибкий выбор вычислительных ресурсов для удовлетворения потребностей обучения разного масштаба:
Выбор места обучения:
-
Локальный GPU (local-gpu) - использование GPU-серверов в локальном дата-центре. Подходит для длительных задач обучения и частного развертывания.
- Поддержка параллельного обучения на нескольких GPU.
- Отображение статуса GPU в реальном времени (использование видеопамяти, температура, загрузка).
- Подходит для больших наборов данных и длительного обучения.
-
Ресурсы публичного облака - аренда мощностей у облачных провайдеров по запросу с оплатой за фактическое время обучения.
- RunPod - поддержка быстрого развертывания GPU-контейнеров.
- AWS EC2/SageMaker/Batch - интеграция с облачными сервисами Amazon.
- Tencent Cloud/Alibaba Cloud - поддержка основных облачных провайдеров.
- Подходит для временных задач обучения или при необходимости расширения ресурсов.
Автоматическое обнаружение платформой:
- Платформа CUDA - автоматическое обнаружение GPU NVIDIA, поддержка ускорения обучения через CUDA.
- Платформа MPS - поддержка ускорения через Metal Performance Shaders для Apple Silicon (M1/M2 и др.).
- Платформа CPU - автоматический переход на обучение на CPU при отсутствии GPU (медленнее, подходит для мелкомасштабных тестов).
Выбор и мониторинг GPU:
- Перед обучением можно просмотреть список доступных GPU и их статус в реальном времени.
- Поддержка ручного выбора конкретных GPU или параллельного использования нескольких GPU.
- Мониторинг загрузки GPU, использования видеопамяти, температуры и т.д. в реальном времени.
- Автоматическая оптимизация распределения видеопамяти для предотвращения нерационального использования ресурсов.
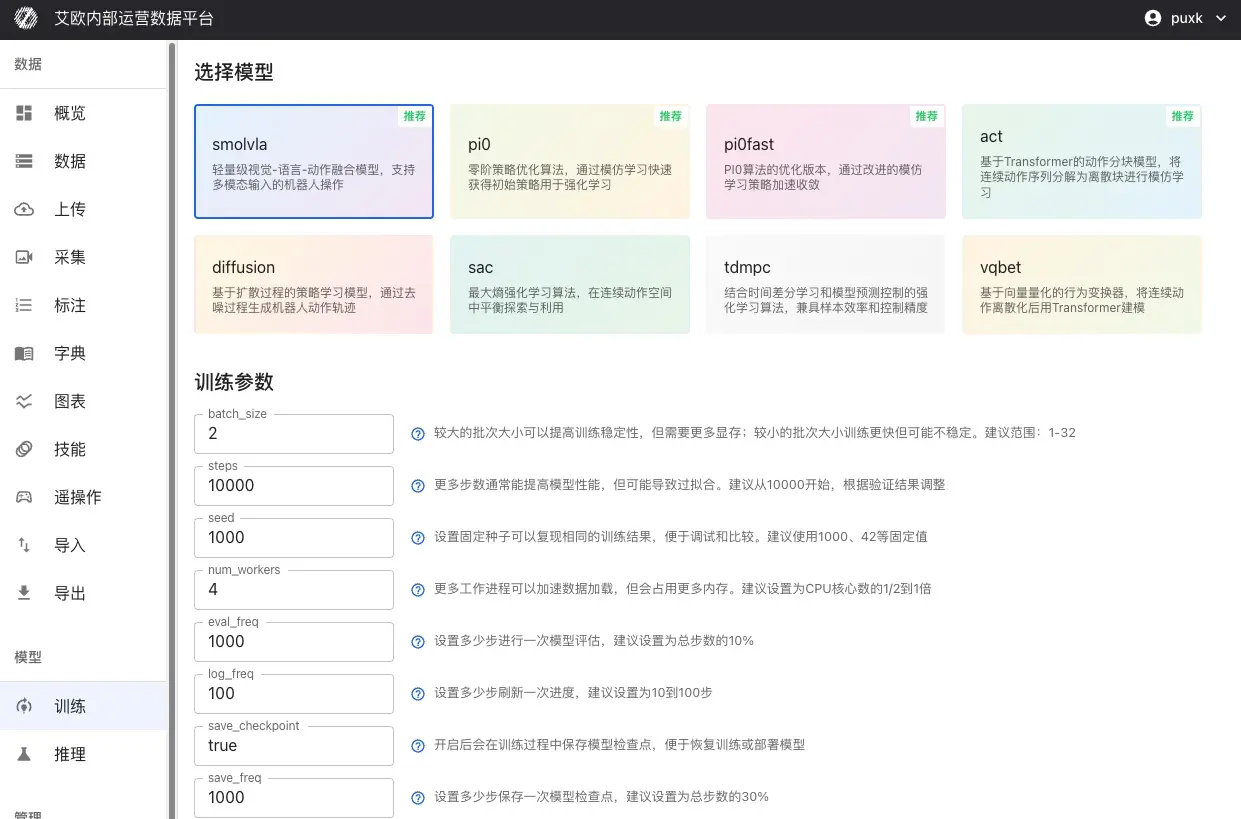
Выбор архитектуры модели
Выберите подходящую модель в соответствии с конкретными требованиями задачи:
- Для задач, требующих понимания инструкций на естественном языке, выбирайте SmolVLA или OpenVLA.
- Для задач имитационного обучения с экспертными демонстрациями выбирайте ACT, Pi0 или Pi0-Fast.
- Для задач, требующих онлайн-обучения, выбирайте SAC или TDMPC.
Настройка параметров обучения
Платформа предоставляет богатый выбор параметров конфигурации обучения для специфических нужд различных моделей:
Общие параметры обучения:
- batch_size (размер батча) - контролирует количество образцов, используемых при каждом шаге обучения. Рекомендуемый диапазон 1–32. Больший батч повышает стабильность обучения, но требует больше видеопамяти.
- steps (количество шагов) - общее количество шагов обучения модели. Рекомендуется начинать с 10 000 и корректировать на основе результатов валидации.
- seed (случайное число) - обеспечивает воспроизводимость результатов обучения. Рекомендуется использовать фиксированные значения, такие как 1000, 42 и т.д.
- num_workers (количество рабочих процессов загрузчика данных) - ускоряет загрузку данных. Рекомендуется устанавливать от 1/2 до 1-кратного количества ядер CPU.
- eval_freq (частота оценки) - через сколько шагов проводить оценку модели. Рекомендуется 10% о�т общего количества шагов.
- log_freq (частота логов) - через сколько шагов выводить логи обучения. Рекомендуется 10–100 шагов.
- save_freq (частота сохранения) - через сколько шагов сохранять чекпоинт. Рекомендуется 30% от общего количества шагов.
- save_checkpoint (сохранять ли чекпоинты) - при включении сохраняет промежуточные состояния модели для возможности возобновления обучения или развертывания.
Параметры оптимизатора:
- optimizer_lr (скорость обучения) - контролирует амплитуду обновления параметров. Рекомендуемый диапазон от 1e-4 до 1e-5. Слишком высокая скорость ведет к нестабильности, слишком низкая — к медленной сходимости.
- optimizer_weight_decay (распад весов) - параметр регуляризации для предотвращения переобучения. Рекомендуемый диапазон от 0.0 до 0.01.
- optimizer_grad_clip_norm (порог обрезки градиента) - предотвращает взрыв градиентов. Рекомендуется установить значение 1.0.
- scheduler_warmup_steps (шаги прогрева скорости обучения) - постепенное увеличение скорости обучения в начале. Рекомендуется 5–10% от общ�его количества шагов.
- scheduler_decay_steps (шаги снижения скорости обучения) - снижение скорости обучения на поздних этапах. Рекомендуется 80–90% от общего количества шагов.
Специфические параметры моделей:
Разные модели поддерживают свои специфические параметры:
-
Модель ACT:
chunk_size(размер фрагмента действия) - длина последовательности действий в одном предсказании. Рекомендуемый диапазон 10–50.n_obs_steps(шаги истории наблюдений) - количество используемых кадров истории. В большинстве случаев используется 1.n_action_steps(шаги выполнения) - количество фактически выполняемых шагов действия, обычно равно chunk_size.vision_backbone(визуальная основа) - выбор из resnet18/34/50/101/152.dim_model(размерность модели) - основная скрытая размерность Transformer. По умолчанию 512.n_heads(количество голов внимания) - количество голов в multi-head attention. По умолчанию 8.
-
Модель Diffusion Policy:
horizon(горизонт предсказания) - длина предсказания действий в диффузионной модели. Рекомендуется 16.num_inference_steps(шаги инференса) - количество шагов сэмплирования. Рекомендуется 10.
-
Модели SmolVLA/OpenVLA:
max_input_seq_len(макс. длина входной последовательности) - ограничение количества токенов на входе. Рекомендуется 256–512.max_decoding_steps(макс. шаги декодирования) - макс. количество итераций генерации последовательности действий. Рекомендуется 256.freeze_lm_head(заморозка головы языковой модели) - рекомендуется включать при тонкой настройке.freeze_vision_encoder(заморозка визуального энкодера) - рекомендуется включать при тонкой настройке.
-
Модели RL, такие как SAC:
latent_dim(размерность латентного пространства) - размерность выхода энкодера. Рекомендуется 256.
Советы по настройке параметров:
- Для первого обучения рекомендуется использовать параметры по умолчанию.
- Корректируйте batch_size в зависимости от объема видеопамяти GPU, чтобы избежать ошибок OOM.
- При тонкой настройке предобученных моделей рекомендуется снижать скорость обучения (1e-5) и замораживать часть слоев.
- Регулярно просматривайте логи и корректируйте скорость обучения в соответствии с кривой потерь.
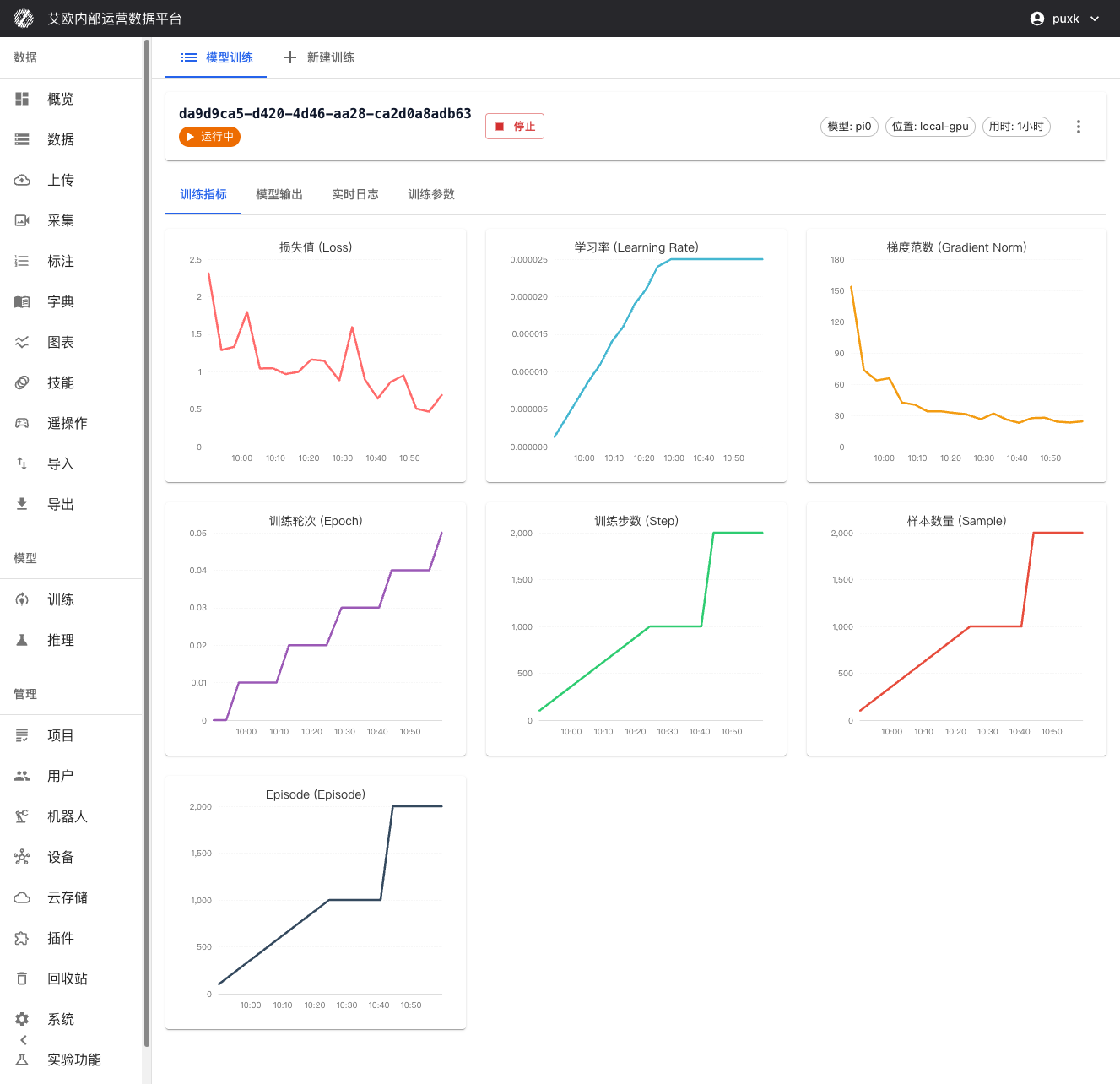
После запуска обучения платформа предоставляет полные функции мониторинга и управления:
3. Выполнение и мониторинг обучения
После запуска платформа предоставляет полные функции мониторинга и управления в реальном времени:
Мониторинг в реальном времени
Визуализация метрик обучения:
- Кривая функции потерь - отображение потерь обучения и валидации в реальном времени для оценки сходимости.
- Метрики точности валидации - отображение производительности модели на проверочном наборе данных.
- Изменение скорости обучения - визуализация выполнения стратегии планировщика скорости обучения.
- Прогресс обучения - отображение выполненных шагов, общего количества шагов, расчетного оставшегося времени и т.д.
Предпросмотр выхода модели:
- Периодический вывод примеров предсказаний в процессе обучения.
- Визуализация результатов предсказания модели на валидационных данных.
- Помогает наблюдать за прогрессом обучения и выявлять потенциальные проблемы.
Системные логи:
- Подробные логи обучения, включающие информацию о каждом шаге.
- Отображение ошибок и предупреждений в реальном времени для быстрой локализации проблем.
- Поддержка потоковой передачи логов для просмотра актуального состояния в любой момент.
Мониторинг ресурсов:
- Мониторинг загрузки GPU и использования видеопамяти в реальном времени.
- Отслеживание использования CPU и оперативной памяти.
- Мониторинг сетевого и дискового ввода-вывода (если применимо).
Управление обучением
Управление процессом:
- Пауза обучения - временная остановка задачи с сохранением текущего прогресса.
- Возобновление обучения - продолжение с момента остановки.
- Остановка обучения - безопасное завершение задачи с сохранением текущего чекпоинта.
- Перезапуск обучения - повторный запуск задачи обучения.
Управление чекпоинтами:
- Автосохранение - автоматическое сохранение состояний модели согласно заданной частоте.
- Список чекпоинтов - просмотр всех сохраненных состояний с информацией о шагах, времени и т.д.
- Загрузка чекпоинтов - возможность скачать файлы чекпоинтов локально.
- Возобновление с чекпоинта - продолжение обучения с любого сохраненного состояния.
- Откат версий - выбор исторических чекпоинтов для отката модели.
Операции с задачами:
- Корректировка параметров - возможность просмотра и изменения некоторых параметров в процессе обучения (использовать с осторожностью).
- Копирование задачи - быстрое создание новой задачи на основе успешной конфигурации.
- Удаление задачи - удаление ненужных задач для освобождения места в хранилище.
Советы по обучению:
- Регулярно проверяйте логи для раннего обнаружения проблем.
- Корректируйте скорость обучения или останавливайте процесс на основе кривой потерь.
- Регулярно сохраняйте чекпоинты для предотвращения потери данных при сбоях.
- Используйте функцию копирования задач для быстрого тестирования различных комбинаций параметров.
4. Оценка и экспорт модели
После завершения обучения платформа предоставляет полные функции оценки, экспорта и развертывания:
Оценка модели
Метрики производительности:
- Автоматический расчет различных метрик на валидационном наборе данных.
- Поддержка множества показателей: точность, коэффициент успеха, ошибка действия и др.
- Предоставление отчетов о производительности и сравнительного анализа.
Сравнение моделей:
- Сравнение производительности моделей из разных задач обучения.
- Визуализация сравнительных графиков по нескольким метрикам.
- Помощь в выборе версии модели с лучшей производительностью.
Управление чекпоинтами
Все сохраненные чекпоинты отображаются на странице деталей �обучения:
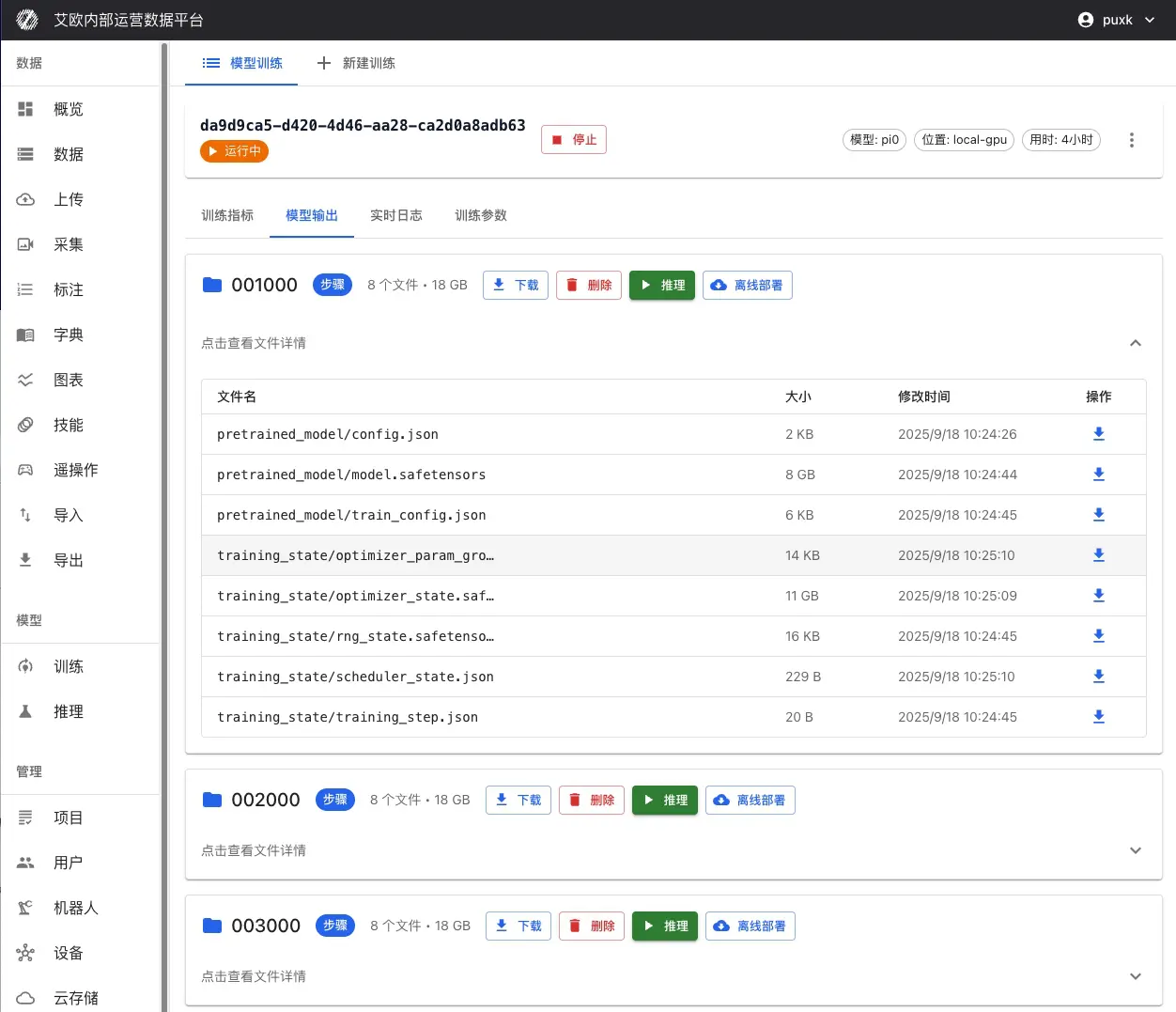
Информация о чекпоинте:
- Имя чекпоинта - автоматически сгенерированное или пользовательское имя (например, "step_1000", "last" и т.д.).
- Шаги обучения - количество шагов, соответствующих этому чекпоинту.
- Время сохранения - временная метка сохранения.
- Размер файла - размер файла чекпоинта.
- Метрики производительности - показатели модели на валидационном наборе.
Операции с чекпоинтами:
- Просмотр деталей - просмотр подробной информации и результатов оценки.
- Загрузка чекпоинта - скачивание файла для офлайн-развертывания или анализа.
- Отметка как лучшего - пометка чекпоинта с лучшими показателями как «Лучшая модель».
- Развертывание инференса - развертывание сервиса инференса из чекпоинта в один клик (подробнее в следующей главе).
Описание чекпоинтов:
- last - последний сохраненный чекпоинт, обычно отражает актуальное состояние модели.
- best - чекпоинт с лучшими показателями на валидационном наборе, обычно используется для промышленного развертывания.
- step_xxx - чекпоинты, сохраненные на определенных шагах, полезны для анализа процесса обучения.
Экспорт модели
После обучения модель можно экспортировать для:
- Офлайн-развертывания локально на роботе.
- Интеграции с другими системами.
- Управления версиями и архивирования.
Теперь вы можете использовать платформу EmbodyFlow для быстрого и удобного обучения собственных специализированных моделей. Чекпоинты обученных моделей можно сразу использовать для развертывания сервисов инференса, как описано в следующей главе, реализуя полный цикл от обучения до применения.