Наборы данных HDF5
HDF5 (Hierarchical Data Format version 5) — это эффективный и гибкий формат хранения данных, широко используемый в области воплощенного интеллекта (Embodied AI). Его иерархическая структура (группы и наборы данных) упрощает организацию и управление сложными мультимодальными данными, обеспечивая высокую скорость чтения/записи и кроссплатформенный обмен.
Импорт данных HDF5
В области воплощенного интеллекта структура и именование файлов HDF5 зависят от производителя оборудования. Платформа адаптирована под основные внешние системы сбора данных (например, AgileX Piper), позволяя напрямую импортировать соответствующие файлы HDF5 для визуализации.
Если ваши данные HDF5 еще не поддерживаются, пожалуйста, свяжитесь с нами и опишите структуру данных. Мы оперативно проведем адаптацию, чтобы ваши мультимодальные данные идеально визуализировались, размечались и экспортировались на платформе.
Экспорт данных HDF5
Платформа поддерживает экспорт р�азмеченных данных из форматов mcap, bag, hdf5 и др. в файлы HDF5 для последующего обучения моделей машинного обучения. Процесс аннотации связывает действия с инструкциями на естественном языке, что позволяет моделям VLA понимать и выполнять голосовые или текстовые команды.
Подробнее об аннотации: Аннотация данных
После завершения разметки в интерфейсе экспорта можно выбрать нужные подмножества данных.
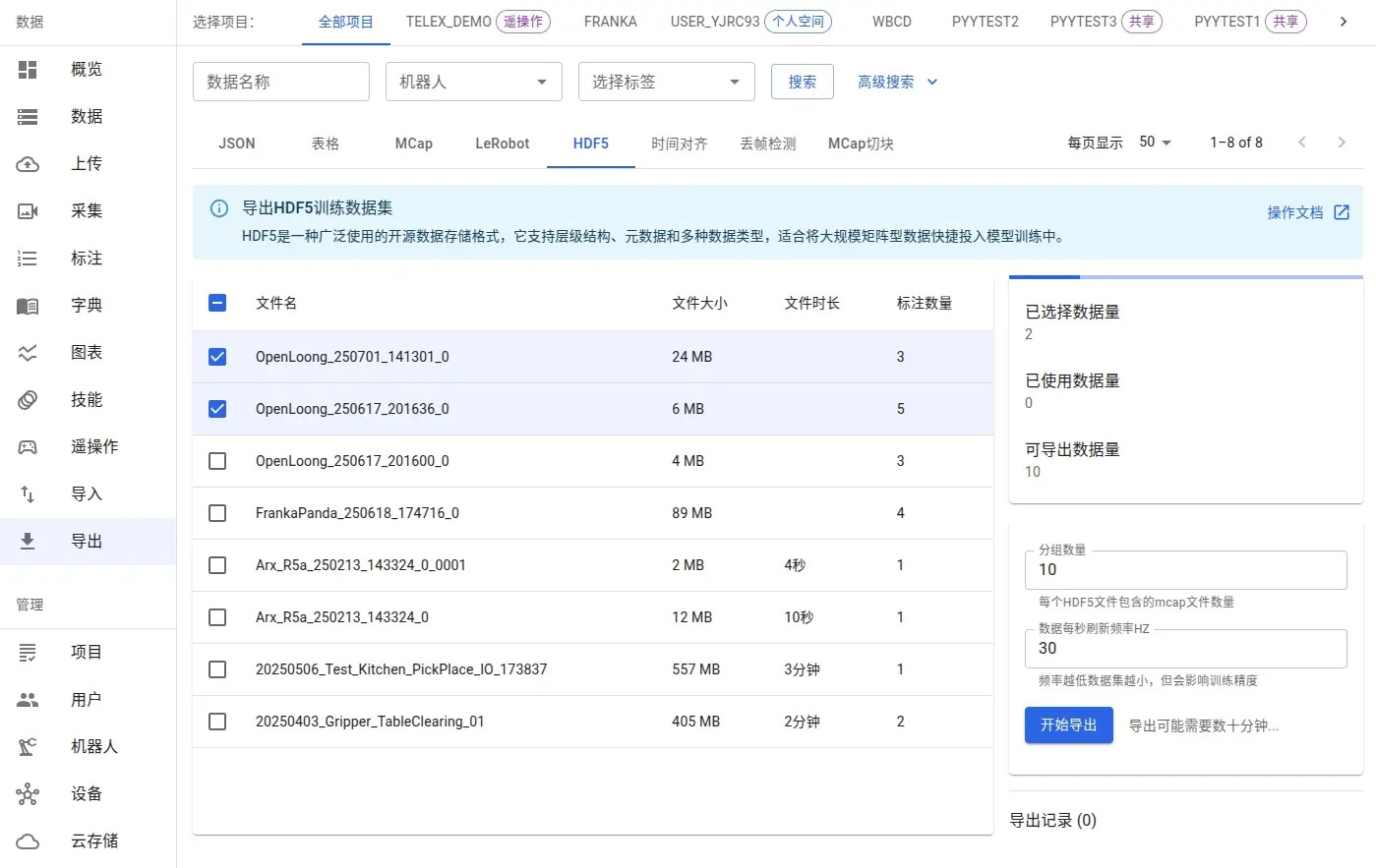
- Количество в группе: Задает число исходных файлов, объединяемых в один HDF5. Для соответствия «один к одному» установите значение 1.
- Частота обновления: Управляет частотой дискретизации данных в секунду, что влияет на размер файла.
После экспорта результат можно просмотреть в интерфейсе:
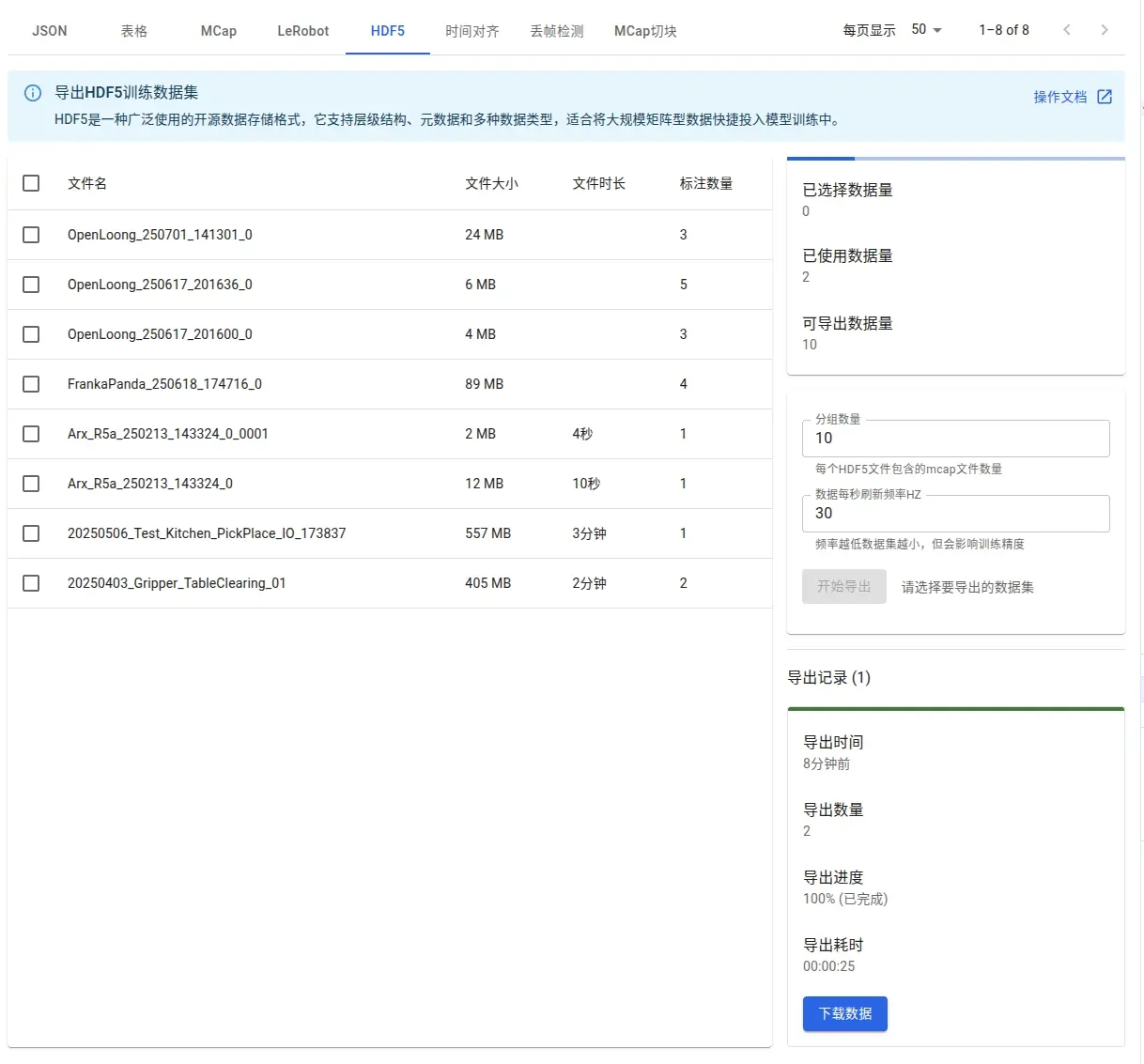
Скачанные данные:

Описание структуры экспортируемых данных
Экспортируемые файлы HDF5 именуются по группам исходных файлов (например, chunk_001.hdf5) и организованы в древовидную структуру:
- Корневая группа (/): Верхний уровень каталога.
- Подгруппы: Например,
/data,/meta.- В
/dataданные разделены по последовательностям задач аннотации (например,episode_001,episode_002).
- В
- Наборы данных (Datasets): Например,
/data/episode_001- Атрибуты включают:
task— аннотация на английском языке.task_zh— аннотация на китайском языке.score— оценка качества действия.
- Сохраняемые данные включают:
action— команды суставам (многомерный массив).observation.images.*— сжатые изображения с разных ракурсов (JPEG).observation.state— значения датчиков (многомерный массив).observation.gripper— значения состояния захвата (многомерный массив).
- Атрибуты включают:
Пример структуры:
HDF5 "./chunk_001.hdf5" {
FILE_CONTENTS {
group /
group /data
group /data/episode_001
dataset /data/episode_001/action
dataset /data/episode_001/observation.gripper
dataset /data/episode_001/observation.images.camera_01
dataset /data/episode_001/observation.images.camera_02
dataset /data/episode_001/observation.images.camera_03
dataset /data/episode_001/observation.images.camera_04
dataset /data/episode_001/observation.state
group /data/episode_002
dataset /data/episode_002/action
dataset /data/episode_002/observation.gripper
dataset /data/episode_002/observation.images.camera_01
dataset /data/episode_002/observation.images.camera_02
dataset /data/episode_002/observation.images.camera_03
dataset /data/episode_002/observation.images.camera_04
dataset /data/episode_002/observation.state
......
group /meta
}
}
Пример чтения файла HDF5
Для работы с файлами HDF5 на Python рекомендуется использовать библиотеку h5py. Базовое использование:
import h5py
# Открытие файла HDF5 в режиме только для чтения
with h5py.File('chunk_001.hdf5', 'r') as f:
# Просмотр групп верхнего уровня
print("Группы верхнего уровня:", list(f.keys()))
# Доступ к наборам данных в группе /data/episode_001
episode_001 = f['/data/episode_001']
print("Наборы данных в episode_001:", list(episode_001.keys()))
# Чтение данных action
action_data = episode_001['action'][:]
print("Данные action:", action_data)
Сценарии применения и преимущества
Формат HDF5 обладает следующими преимуществами для воплощенного интеллекта:
- Поддержка хранения масштабных мультимодальных данных (изображения высокого разрешения, данные датчиков и т.д.).
- Встроенное сжатие данных для экономии места.
- Кроссплатформенная совместимость для легкого обмена и миграции.
- Гибкая иерархия, подходящая для сложных задач и управления разнообразными данными.
Правильное проектирование структуры HDF5 в сочетании с инструментами платформы позволяет эфф�ективно управлять сложными данными, способствуя научным исследованиям и обучению моделей.
Обучение моделей роботов
Экспортированные данные HDF5 могут напрямую использоваться для обучения различных моделей, включая имитационное обучение (Imitation Learning), обучение с подкреплением (RL) и модели Видение-Язык-Действие (VLA).
Подробные методы обучения и примеры кода см. в: Использование данных HDF5 для обучения моделей роботов