HDF5データセット
HDF5(Hierarchical Data Format version 5)は、効率的で柔軟なデータ保存形式であり、具身知能(Embodied AI)分野で広く利用されています。その階層構造(グループとデータセット)により、マルチモーダルな複雑なデータの整理と管理が容易になり、効率的なデータの読み書きとクロスプラットフォームでの共有をサポートします。
HDF5データのインポート
具身知能の分野では、HDF5ファイルの構造や命名規則はデバイスメーカーによって異なります。プラットフォームは主要な外部データ収集システム(松霊Piperなど)に対応しており、関連するHDF5ファイルを直接インポートして視覚化することができます。
お使いのHDF5データがまだサポートされていない場合は、データ構造を添えてお問い合わせください。迅速に対応を完了し、お客様のマルチモーダルデータがプラットフォーム上で完璧に視覚化、アノテーション、エクスポートできるようにいたします。
HDF5データのエクスポート
プラットフォームは、mcap、bag、hdf5などの形式のデータをアノテーションした後にHDF5ファイルとしてエクスポートすることをサポートしており、その後の機械学習モデルのトレーニングに役立てることができます。アノテーションプロセスによって動作と自然言語命令が関連付けられ、VLAモデルが言語コマンドを理解し実行できるようになります。
アノテーション操作の詳細は以下を参照してください:データアノテーション
アノテーション完了後、エクスポートインターフェースで必要なデータのサブセットを選択してエクスポートできます。
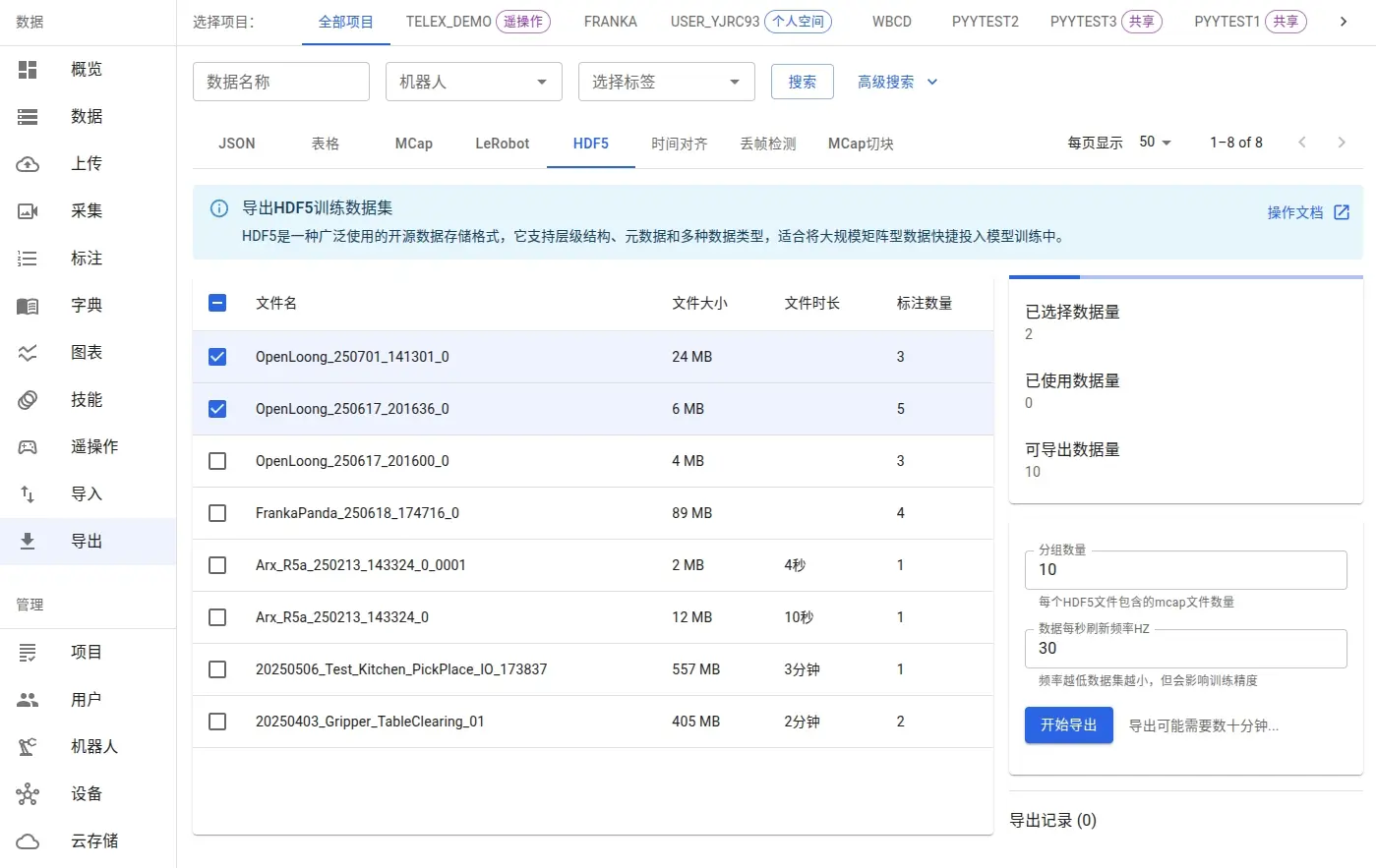
- グループ数:各HDF5ファイルに含まれる元のファイル数を設定します。1対1に対応��させる場合は、1に設定します。
- データ更新頻度:1秒あたりのデータ収集回数を制御し、ファイルサイズに影響します。
エクスポート後、インターフェースで結果を確認できます:
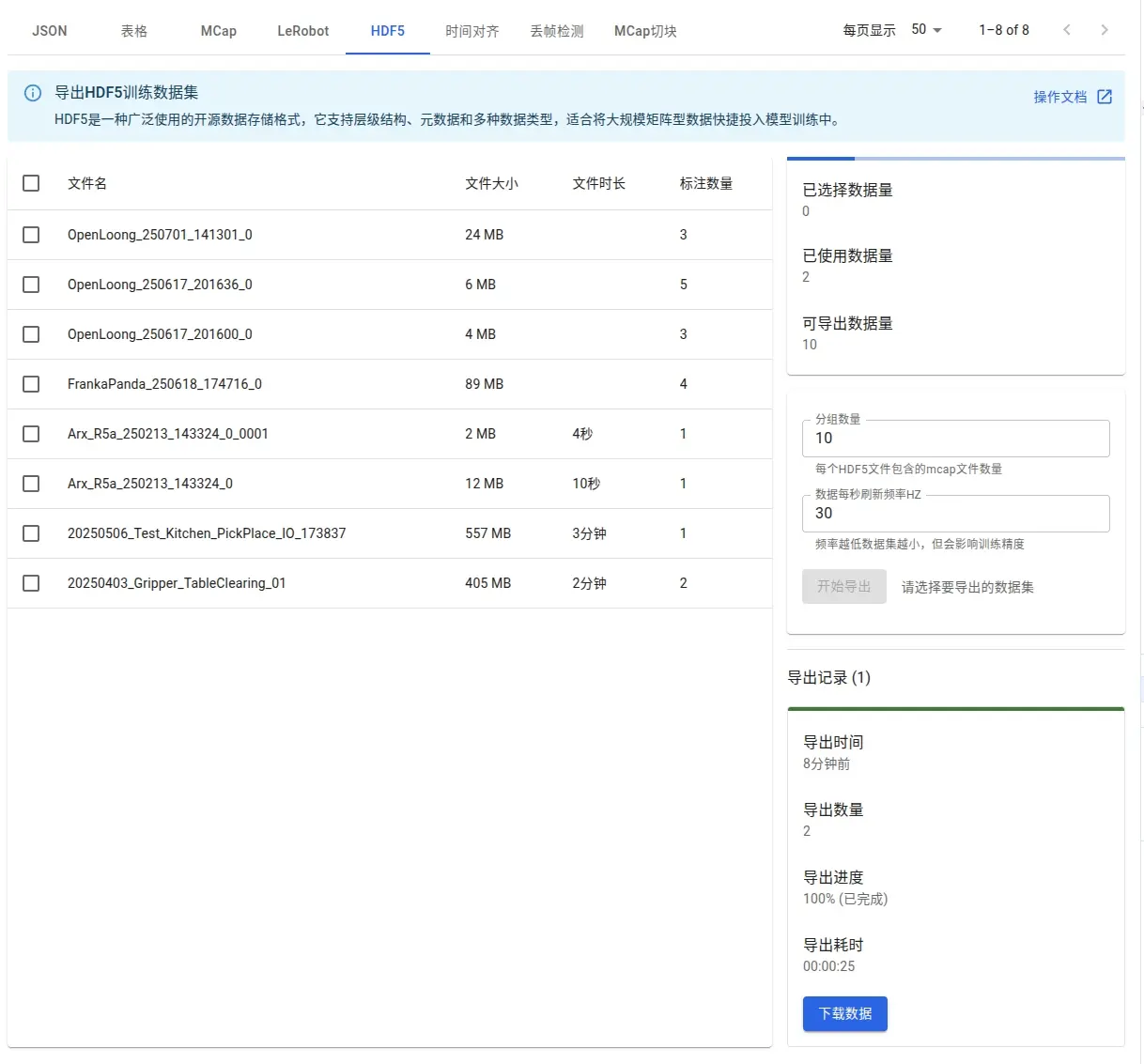
ダウンロード後のデータ:

エクスポートデータの構造説明
エクスポートされたHDF5ファイルは、元のファイルごとにグループ化して命名され(例:chunk_001.hdf5)、ツリー構造でデータを整理します:
- ルートグループ(/):トップレベルディレクトリ。
- サブグループ:
/data、/metaなど。/data以下は、アノテーションタスクのシーケンスごとにサブグループに分かれます(例:episode_001、episode_002)。
- データセット:
/data/episode_001など- 属性値(Attributes)には以下が含まれます:
taskアノテーションされた自然言語(英語)task_zhアノテーションされた自然言語(中国語)score動作品質スコア
- 保存されるデータには以下が含まれます:
action下達された関節指令 (多次元配列)observation.images.*各視点の圧縮画像 (JPEG)observation.stateセンサーの観測値 (多次元配列)observation.gripperグリッパー閉合状態の観測値 (多次元配列)
- 属性値(Attributes)には以下が含まれます:
構造の例は以下の通りです:
HDF5 "./chunk_001.hdf5" {
FILE_CONTENTS {
group /
group /data
group /data/episode_001
dataset /data/episode_001/action
dataset /data/episode_001/observation.gripper
dataset /data/episode_001/observation.images.camera_01
dataset /data/episode_001/observation.images.camera_02
dataset /data/episode_001/observation.images.camera_03
dataset /data/episode_001/observation.images.camera_04
dataset /data/episode_001/observation.state
group /data/episode_002
dataset /data/episode_002/action
dataset /data/episode_002/observation.gripper
dataset /data/episode_002/observation.images.camera_01
dataset /data/episode_002/observation.images.camera_02
dataset /data/episode_002/observation.images.camera_03
dataset /data/episode_002/observation.images.camera_04
dataset /data/episode_002/observation.state
......
group /meta
}
}
HDF5ファイルの読み込み例
HDF5ファイルの読み込みと操作には、Pythonの h5py ライブラリの使用を推奨します。基本的な使い方は以下の通りです:
import h5py
# 読み取り専用モードでHDF5ファイルを開く
with h5py.File('chunk_001.hdf5', 'r') as f:
# トップレベルグループを表示
print("トップレベルグループ:", list(f.keys()))
# /data/episode_001 グループ下のデータセットにアクセス
episode_001 = f['/data/episode_001']
print("episode_001 下のデータセット:", list(episode_001.keys()))
# action データセットを読み込む
action_data = episode_001['action'][:]
print("action データ:", action_data)
活用シーンとメリット
HDF5形式は具身知能分野において以下のメリットがあります:
- 大規模なマルチモーダルデータ(高解像度画像、センサーデータなど)の保存をサポート
- 内蔵のデータ圧縮によりストレージ容量を節約
- クロスプラットフォーム互換性により、データの共有と移行が容易
- 柔軟なデータ階層構造により、複雑なタスクや多様なデータ管理に適している
HDF5構造を適切に設計し、プラットフォームのツールと組み合わせることで、具身知能に関連する複雑なデータを効率的に管理・処理し、科学研究やモデルトレーニングを強力にサポートします。
ロボットモデルのトレーニング
エクスポートされたHDF5データは、模倣学習、強化学習、視覚-言語-動作(VLA)モデルなど、様々なロボット学習モデルのトレーニングに直接使用できます。
詳細なトレーニング方法とコード例は以下を参照してください:ロボットモデルトレーニングのためのHDF5データの活用