LeRobotデータセット
LeRobot は Hugging Face がオープンソース化したロボット学習データ標準化フレームワークであり、ロボット学習および強化学習のシナリオ向けに特別に設計されています。統一されたデータ形式仕様を提供することで、研究者がロボット学習の実験をより簡単に共有、比較、再現できるようにし、異なる研究プロジェクト間でのデータ形式変換コストを大幅に削減します。
データのエクスポート
以下の図は、アノテーション済みデータからモデル訓練までの流れをまとめています。エクスポート形式を選択しパラメータを設定、エクスポートしてダウンロード・解凍後、LeRobot や OpenPI で Pi0、SmolVLA、ACT などのモデルを訓練できます。
艾欧データプラットフォーム(EmbodiFlow)は、LeRobot 標準形式のデータエクスポートを完全にサポートしており、VLA(Vision-Language-Action)モデルのトレーニングプロセスに直接使用できます。エクスポートされたデータには、ロボット操作の完全なマルチモーダル情報(視覚知覚データ、自然言語命令、および対応するアクションシーケンス)が含まれており、完全な「知覚-理解-実行」のクローズドループ・データマッピングを形成します。
LeRobot 形式のデータエクスポートには、高い計算リソースが必要です。艾欧データ開放プラットフォームの無料版では、各ユーザーのエクスポート数に合理的な制限が設けられていますが、有料版では無制限のエクスポートサービスを提供し、GPU 加速機能を備えているため、エクスポート処理速度を大幅に向上させることができます。
1. エクスポートデータの選択
データエクスポートの前にアノテーション作業を完了す�る必要があります。アノテーションプロセスは、ロボットのアクションシーケンスと対応する自然言語命令の間に正確なマッピング関係を確立するもので、これは VLA モデルをトレーニングするための必須の前提条件です。このマッピングを通じて、モデルは言語コマンドを理解し、それを正確なロボット制御アクションに変換することを学習します。
データアノテーションの具体的な流れやバッチアノテーションのヒントについては、データアノテーションガイドを参照してください。
アノテーション完了後、エクスポートインターフェースですべてのアノテーション済みデータセットを確認できます。システムは柔軟なデータサブセットの選択をサポートしており、必要に応じて特定のデータを選択してエクスポートできます。
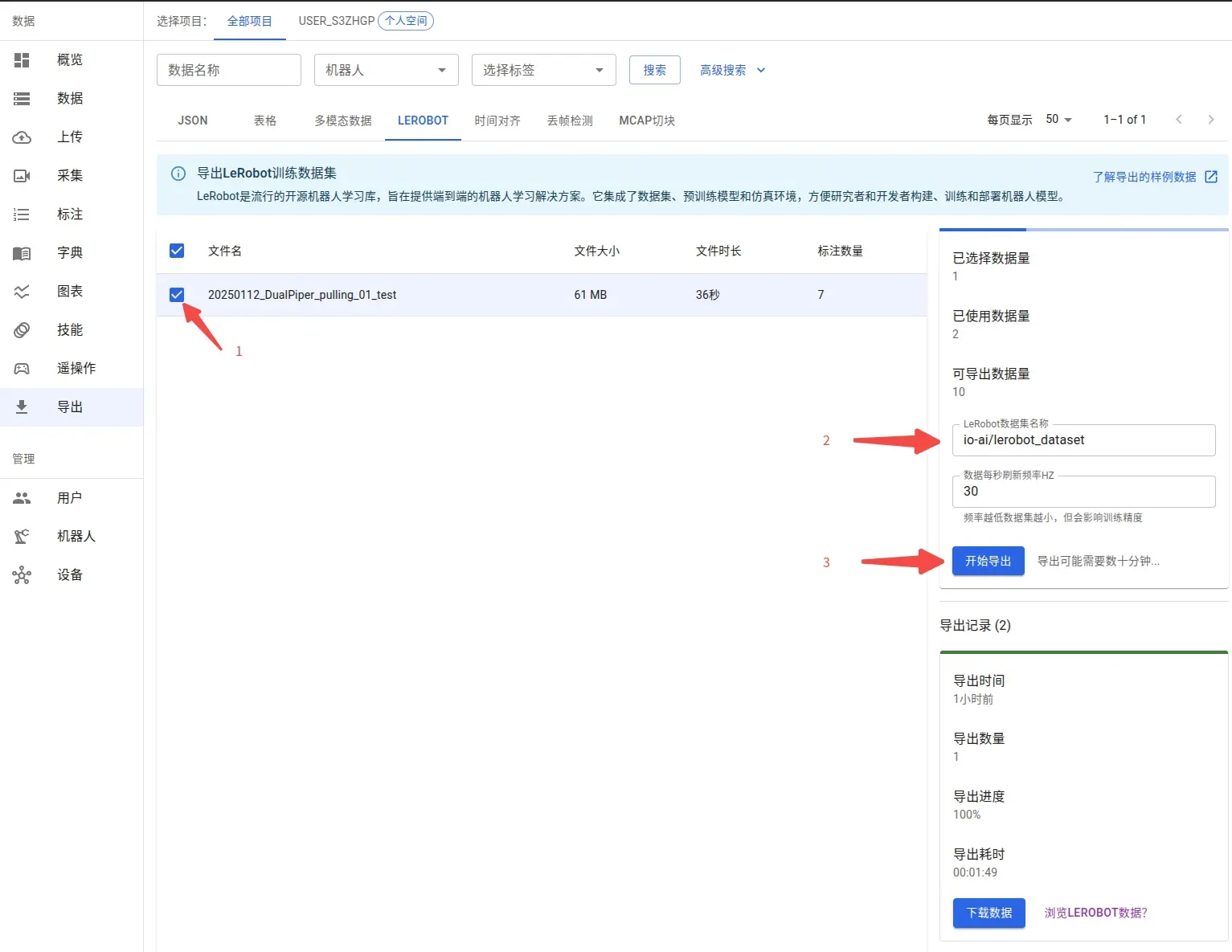
データセットの命名はカスタマイズ可能です。データセットを Hugging Face プラットフォームに公開する予定がある場合は、標準のリポジトリ命名形式(例:myproject/myrepo1)を採用することをお勧めします。これにより、その後のモデルの共有やコラボレーションが容易になります。
エクスポート設定オプション
エクスポートインターフェースの右側にある設定パネルで、以下のエクスポートパラメータを設定できます:
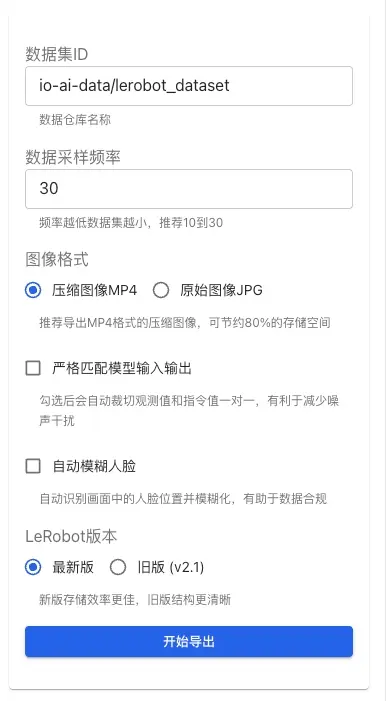
データサンプリング周波数:データサンプリングの頻度を制御します(推奨 10-30 Hz)。周波数が低いほど、生成されるデータセットのサイズは小さくなりますが、一部の詳細情報が失われる可能性があります。
画像形式:
- MP4(推奨):圧縮画像形式。ストレージ容量を約 80% 節約でき、大規模なデータセットのエクスポートに適しています。
- JPG:元の画像形式。完全な画質を維持しますが、ファイルサイズは大きくなります。
モデル入出力の厳密な一致:有効にすると、システムが観測値と命令値を自動的にクロップし、1対1の対応関係を確保します。これにより、ノイズ干渉が減少し、トレーニングデータの品質が向上します。
顔の自動ぼかし:有効にすると、システムが画面内の顔の位置を自動的に識別し、ぼかし処理を行います。この機能は以下の点で役立ちます:
- 個人のプライバシーを保護し、データのコンプライアンス要件に適合させる。
- オペレーターが映り込んでいるデータセットに適している。
- エクスポートされるすべての画像内の顔情報を自動的に処理する。
データ量が多いほど、エクスポートに時間がかかります。すべてのデータを一度に処理するのではなく、タスクタイプごとに分類してエクスポートすることをお勧めします。バッチエクスポートは処理速度を向上させるだけでなく、その後のデータ管理、バージョン管理、および特定のモデルトレーニングにも役立ちます。
2. エクスポートファイルのダウンロードと解凍
エクスポートにかかる時間はデータの規模や現在のシステム負荷に依存し、通常は数十分かかります。ページは自動的に進捗ステータスを更新しますので、後で戻って処理結果を確認してください。
エクスポートが完了すると、ページ右側の エクスポート履歴 エリアに データ��をダウンロード ボタンが表示されます。クリックすると .tar.gz 形式の圧縮ファイルパッケージを取得できます。

他のデータと混同しないよう、ローカルに専用のディレクトリ(例:~/Downloads/mylerobot3)を作成してファイルを解凍することをお勧めします:

解凍後のファイルは LeRobot データセットの標準形式仕様に厳密に従っており、完全なマルチモーダルデータ(視覚知覚データ、ロボット状態情報、アクションラベルなど)が含まれています:

3. カスタムトピックマッピング
LeRobot データセットをエクスポートする際、システムは ROS/ROS2 トピックを LeRobot 標準形式の観測値(observation.state)およびアクション(action)フィールドにマッピングする必要があります。カスタムデータセットを正しくエクスポートするには、トピックマッピングの規則を理解することが重要です。
デフォルトのトピックマッピング規則
艾欧データプラットフォームは、トピック名の接尾辞に基づく自動識別メカニズムを採用しています:
観測値(observation.state)のマッピング規則:
- トピック名が
/joint_stateまたは/joint_statesで終わる場合、システムはそのpositionフィールド値を自動的に観測値として識別し、observation.stateフィールドにマッピングします。 - 例:
io_teleop/joint_states、/arm/joint_stateなどのトピックは観測値として識別されます。
アクション(action)のマッピング規��則:
- トピック名が
/joint_cmdまたは/joint_commandで終わる場合、システムはそのpositionフィールド値を自動的にアクション指令として識別し、actionフィールドにマッピングします。 - 例:
io_teleop/joint_cmd、/arm/joint_commandなどのトピックはアクション値として識別されます。
データを正しくエクスポートするために、データ録製時には上記の命名規則に従うことをお勧めします。ロボットシステムで異なる命名スタイルを使用している場合は、テクニカルサポートチームに連絡して適合させてください。
カスタムトピックのサポート
デフォルトの規則に従わないカスタムトピックを作成した場�合は、以下の方法で対処できます:
-
トピックのリネーム:データ録製段階で、カスタムトピックをデフォルトの規則に従う名称(例:
/joint_statesまたは/joint_command)に変更します。 -
テクニカルサポートへの連絡:トピック名を変更できない場合は、艾欧プラットフォームのテクニカルサポートチームに連絡してください。お客様の特定の命名スタイルに合わせて適合させ、データが正しく LeRobot 形式にマッピングされるようにします。
現在のバージョンでは、エクスポートインターフェースで直接カスタムトピックマッピングを指定することはできません。特別な要件がある場合は、事前にテクニカルサポートチームに相談することをお勧めします。エクスポート前に対応する設定適合を完了させます。
データの視覚化と検証
ユーザーがデータ内容を素早く理解し検証できるように、LeRobot は複数のデータ視覚化ソリューションを提供しています。それぞれのソリューションには適したシーンと独自の利点がありますが、艾欧(EmbodiFlow)データプラットフォームでは LeRobot Studio の使用を推奨しています:
| 使用シーン | 視覚化ソリューション | 主な利点 |
|---|---|---|
| 高速なプライバシープレビュー (推奨) | LeRobot Studio (Web) | インストール不要、アップロード不要、プライバシー保護、ドラッグ&ドロップ |
| ローカル開発・デバッグ | Rerun SDK ローカル表示 | フル機能、高度なインタラクション、オフライン利用可能 |
| 公開共有・展示 | Hugging Face オンライン表示 | コミュニティコラボレーション、共有が容易、いつでもアクセス可能 |
1. LeRobot Studio を使用したオンライン視覚化 (推奨)
艾欧(EmbodiFlow)データプラットフォームは、ネイティブに統合された LeRobot 視覚化ツール —— LeRobot Studio を提供しています�。これは現在最も便利なデータプレビューソリューションであり、ローカル環境をインストールする必要も、データを Hugging Face にアップロードする必要もありません。ブラウザ上で直接ローカルデータの迅速な視覚化と検証を完了できます。
オンライン体験アドレス:https://io-ai.tech/lerobot/
コアな利点
- 使用障壁ゼロ:Python 環境の設定や Rerun SDK のインストールは不要です。
- プライバシーとセキュリティ:ローカルデータファイルのドラッグ&ドロップによるプレビューをサポートします。データはクラウドサーバーを経由せず、データプライバシーを完全に保証します。
- シームレスな統合:艾欧データプラットフォームは LeRobot データのエクスポートと視覚化分析機能を統合しており、いつでもどこでも利用可能です。
- 完全な機能:LeRobot 標準形式のマルチモーダルデータ再生(画像、状態、アクション)を完全にサポートしています。
使用方法
- LeRobot Studio に�アクセスします。
- ページ上の 「ファイルを選択」 ボタンをクリックするか、エクスポートされた
.tar.gzデータパッケージ(または解凍されたフォルダ)をウィンドウに直接ドラッグします。 - システムがデータ構造を自動的に解析し、即座にインタラクティブな再生を開始します。
2. Rerun SDK を使用したローカル視覚化
ローカルに lerobot リポジトリをインストールすることで、組み込みの lerobot/scripts/visualize_dataset.py スクリプトと Rerun SDK を使用して、タイムライン形式のインタラクティブなマルチモーダルデータ視覚化を実現できます。この方法では、画像、状態、アクションなどの多次元情報を同時に表示でき、最も豊富なインタラクション機能とカスタマイズオプションを提供します。
環境準備と依存関係のインストール
Python のバージョンが 3.10 以上であることを確認し、以下のインストールコマンドを実行してください:
# Rerun SDK のインストール
python3 -m pip install rerun-sdk==0.23.1
# LeRobot 公式リポジトリのクローン
git clone https://github.com/huggingface/lerobot.git
cd lerobot
# LeRobot 開発環境のインストール
pip install -e .
データの視覚化を開始
python3 -m lerobot.scripts.visualize_dataset \
--repo-id io-ai-data/lerobot_dataset \
--root ~/Downloads/mylerobot3 \
--episode-index 0
パラメータ説明:
--repo-id:Hugging Face データセットの識別子(例:io-ai-data/lerobot_dataset)--root:ローカルの LeRobot データセット保存パス。解凍後のディレクトリを指します。--episode-index:視覚化するエピソードのインデックス番号を指定します(0から開始)。
オフライン視覚化ファイルの生成
視覚化結果を Rerun 形式ファイル(.rrd)として保存し、オフラインでの確認やチームメンバーとの共有に利用できます:
python3 -m lerobot.scripts.visualize_dataset \
--repo-id io-ai-data/lerobot_dataset \
--root ~/Downloads/mylerobot3 \
--episode-index 0 \
--save 1 \
--output-dir ./rrd_out
# 保存された視覚化ファイルをオフラインで確認
rerun ./rrd_out/lerobot_pusht_episode_0.rrd
リモート視覚化(WebSocket モード)
リモートサーバーでデータを処理し、ローカルで確認する必要がある場合は、WebSocket 接続モードを使用できます:
# サーバー側で視覚化サービスを起動
python3 -m lerobot.scripts.visualize_dataset \
--repo-id io-ai-data/lerobot_dataset \
--root ~/Downloads/mylerobot3 \
--episode-index 0 \
--mode distant \
--ws-port 9091
# ローカルからリモート視覚化サービスに接続
rerun ws://サーバーのIPアドレス:9091
3. Hugging Face Spaces を使用したオンライン視覚化
ローカル環境をインストールしたくない場合、LeRobot ��は Hugging Face Spaces に基づくオンライン視覚化ツールを提供しており、ローカルの依存関係なしで使用できます。この方法は、データのクイックプレビューやチームでのデータセット共有に特に適しています。
オンライン視覚化機能を使用するには、データを Hugging Face オンラインリポジトリにアップロードする必要があります。Hugging Face の無料アカウントは公開リポジトリの視覚化のみをサポートしており、データが一般に公開されることに注意してください。データに機密情報が含まれており、非公開を維持する必要がある場合は、ローカル視覚化ソリューションを使用することをお勧めします。
操作手順
- オンライ�ン視覚化ツールにアクセス:https://huggingface.co/spaces/lerobot/visualize_dataset
- Dataset Repo ID フィールドにデータセット識別子を入力します(例:
io-intelligence/piper_uncap_pen) - 左側のパネルで確認したいタスク番号を選択します(例:
Episode 0) - ページ上部に複数の再生オプションが用意されており、最適な表示方法を選択できます。
モデルトレーニングガイド
LeRobot データセットに基づくモデルトレーニングは、ロボット学習を実現するための核心的なステップです。モデルアーキテクチャによってトレーニングパラメータやデータ前処理の要件が異なるため、適切なモデル戦略を選択することがトレーニング効果にとって重要です。
モデル選択戦略
現在の主要な VLA モデルには以下が含まれます:
| モデルタイプ | 適用シーン | 主な特徴 | 推奨用途 |
|---|---|---|---|
| smolVLA | 単一GPU環境、迅速なプロトタイピング | 適度なパラメータ数、効率的なトレーニング | コン��シューマー向けGPU、概念実証 |
| Pi0 / Pi0.5 | 複雑なタスク、マルチモーダル融合 | 最先端の VLA モデル、強力な汎化能力 | 本番環境、複雑なロボットインタラクション |
| ACT | 単一タスクの最適化 | 高いアクション予測精度 | 特定タスク、高頻度制御 |
| Diffusion | 滑らかなアクション生成 | 拡散モデルベース、高い軌道品質 | 滑らかな軌道が必要なタスク |
| VQ-BeT | アクションの離散化 | ベクトル量子化、高速推論 | リアルタイム制御シナリオ |
| TDMPC | モデル予測制御 | サンプル効率が高い、オンライン学習 | データ不足のシナリオ |
Pi0/Pi0.5 モデルのファインチューニングには OpenPI フレームワークを使用する必要があります。 データは LeRobot v2.1 形式でエクスポートされますが、トレーニングプロセスは LeRobot CLI とは異なります。
詳細なファインチューニングガイドは、以下を参照してください:Pi0 および Pi0.5 モデルファインチューニングガイド
smolVLA トレーニング詳細(入門推奨)
smolVLA はコンシューマー向け/単一GPU環境に最適化された VLA モデルです。ゼロからトレーニングするよりも、公式の事前学習済み重みに基づいてファインチューニングすることを強くお勧めします。これにより、トレーニング時間を大幅に短縮し、最終的な効果を向上させることができます。
LeRobot のトレーニングコマンドは以下のパラメータ形式を使用します:
- ポリシータイプ:
--policy.type smolvla(使用するモデルを指定) - パラメータ値:スペース区切り、例:
--batch_size 64(--batch_size=64ではない) - ブール値:
true/falseを使用、例:--save_checkpoint true - リスト値:スペース区切り、例:
--policy.down_dims 512 1024 2048 - モデルのアップロード:デフォルトでは
--policy.push_to_hub falseを追加して、Hugging Face Hub への自動アップロードを無効にする必要があります。
環境準備
# LeRobot リポジトリをクローン
git clone https://github.com/huggingface/lerobot.git
cd lerobot
# smolVLA をサポートするフル環境のインストール
pip install -e ".[smolvla]"
ファインチューニング(推奨案)
- デフォルトではローカルデータセットの使用を推奨:トレーニングデータは通常大きいため、ローカルの解凍ディレクトリを直接使用することをお勧めします。
--dataset.repo_id local/xxx--dataset.root /path/to/dataset(ディレクトリ内にはmeta.json、data/などが含まれている必要があります)
- すでにデータを Hugging Face Hub にアップロードしている場合:
--dataset.repo_id your-name/your-repoだけを残し、--dataset.rootを削除できます。
ローカルデータセットによるファインチューニングの例(デフォルト推奨)
# 例:データがローカルディレクトリ(meta.json, data/ などを含む)にある場合
DATASET_ROOT=~/Downloads/mylerobot3
lerobot-train \
--policy.type smolvla \
--policy.pretrained_path lerobot/smolvla_base \
--dataset.repo_id local/mylerobot3 \
--dataset.root ${DATASET_ROOT} \
--output_dir /data/lerobot_smolvla_finetune \
--batch_size 64 \
--steps 20000 \
--policy.optimizer_lr 1e-4 \
--policy.device cuda \
--policy.push_to_hub false \
--save_checkpoint true \
--save_freq 5000
実践的なアドバイス:
- データ準備:異なる物体の位置、姿勢、環境の変化をカバーするために、50 以上のタスクデモンストレーションクリップを録製することをお勧めします。
- トレーニングリソース:単一の A100 で 20k ステップのトレーニングには約 4 時間かかります。コンシューマー向け GPU では
batch_sizeを下げるか、勾配累積を有効にしてください。 - ハイパーパラメータ調整:
batch_size=64、num_train_steps=20k、学習率1e-4からファインチューニングを開始することをお勧めします。 - ゼロからトレーニングする場合:大規模なデータセット(数千時間)を所有している場合にのみ、
--policy.type=smolvlaでゼロからトレーニングすることを検討してください。
ゼロからのトレーニング(上級ユーザー向け)
# ゼロからのトレーニング(ローカルデータセットの例)
DATASET_ROOT=~/Downloads/mylerobot3
lerobot-train \
--policy.type smolvla \
--dataset.repo_id local/mylerobot3 \
--dataset.root ${DATASET_ROOT} \
--output_dir /data/lerobot_smolvla_fromscratch \
--batch_size 64 \
--steps 200000 \
--policy.optimizer_lr 1e-4 \
--policy.device cuda \
--policy.push_to_hub false \
--save_checkpoint true \
--save_freq 10000
パフォーマンス最適化のヒント
ビデオメモリ(VRAM)の最適化:
# ビデオメモリ使用量を最適化するために以下のパラメータを追加
--policy.use_amp true \
--num_workers 2 \
--batch_size 32 # バッチサイズを小さくする
トレーニングの監視:
- Weights & Biases (W&B) を構成して、トレーニング曲線と評価指標を監視します。
- 合理的な検証間隔と早期停止(Early Stopping)戦略を設定します。
- トレーニングの中断に備えて、定期的にチェックポイントを保存します。
ACT モデルトレーニングガイド
ACT(Action Chunking Transformer)は、単一タスクまたは短時間の�シーケンスポリシー学習向けに設計されています。マルチタスクの汎化能力では smolVLA に劣りますが、タスクが明確で制御周波数が高く、シーケンスが比較的短いシーンでは、依然としてコストパフォーマンスの高い選択肢です。
ACT モデルでは policy.n_action_steps ≤ policy.chunk_size である必要があります。設定ミスを避けるため、両方のパラメータを同じ値(例:100)に設定することをお勧めします。
データ前処理の要件
軌道処理:
- 統一されたクリップの長さと時間の整合性を確保します(推奨 10-20 ステップのアクションチャンク)。
- アクションデータを正規化し、スケールと単位を統一します。
- 観測データの一貫性を維持します(特にカメラの内参と視角)。
トレーニング構成:
ローカルデータセットによるトレーニングの例(デフォルト推奨)
DATASET_ROOT=~/Downloads/mylerobot3
lerobot-train \
--policy.type act \
--dataset.repo_id local/mylerobot3 \
--dataset.root ${DATASET_ROOT} \
--output_dir /data/lerobot_act_finetune \
--batch_size 8 \
--steps 100000 \
--policy.chunk_size 100 \
--policy.n_action_steps 100 \
--policy.n_obs_steps 1 \
--policy.optimizer_lr 1e-5 \
--policy.device cuda \
--policy.push_to_hub false \
--save_checkpoint true \
--save_freq 10000
ハイパーパラメータ調整のアドバイス:
- バッチサイズ:8 から開始し、ビデオメモリに合わせて調整します(ACT は小さめのバッチを推奨)。
- 学習率:1e-5 を推奨。ACT は学習率に敏感です。
- トレーニングステップ数:タスクの複雑さに応じて 100k-200k ステップ。
- アクションブロックサイズ:chunk_size と n_action_steps は 100 に設定することをお勧めします。
- 正則化:過学習が発生した場合は、データの多様性を増やすか早期停止を行います。
パフォーマンス調整戦略
過学習(Overfitting)への対処:
- データ収集の多様性を増やします。
- 適切な正則化技術を適用します。
- 早期停止戦略を実施します。
学習不足(Underfitting)への対処:
- トレーニングステップ数を増やします。
- 学習率のスケジュールを調整します。
- データの品質と一貫性をチェックします。
よくある質問 (FAQ)
データエクスポート関連
Q: LeRobot データのデクスポートにはどのくらい時間がかかりますか?
A: エクスポート時間は主にデータの規模と現在のシステム負荷に依存します。通常、1 GB のデータにつき 3〜5 分の処理時間がかかります。効率向上のため、大きすぎるデータセットを一度に処理するのではなく、タスクタイプごとにバッチに分けてエクスポートすることをお勧めします。
Q: 無料版にはどのようなエクスポート制限がありますか?
A: 無料版では、各ユーザーのエクスポート数と頻度に合理的な制限があり、具体的な制限額はエクスポートインターフェースに表示されます。大規模なデータエクスポートが必要な場合は、無制限のエクスポートと GPU 加速サービスを享受できる有料版へのアップグレードをお勧めします。
Q: エクスポートされたデータの完全性を検証するにはどうすればよいですか?
A: LeRobot 内蔵の検証ツールを使用してチェックしてください:
python -m lerobot.scripts.validate_dataset --root /path/to/dataset
Q: エクスポートされたデータセットが大きすぎる場合はどうすればよいですか?
A: 以下の方法で最適化できます:
- エクスポート周波数を下げる(デフォルト 30fps を 10-15fps に下げる)。
- 時間帯やタスクタイプごとに分割してエクスポートする。
- 画像品質を圧縮する(トレーニング効果を保証できる範囲内で)。
データの視覚化関連
Q: Rerun SDK のインストールに失敗した場合はどうすればよいですか?
A: 以下の条件を確認してください:
- Python のバージョンが 3.10 以上であること。
- ネットワーク接続が安定していること。
- 仮想環境でのインストールを試す:
python -m venv rerun_env && source rerun_env/bin/activate - ミラーサイトを使用する:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple rerun-sdk==0.23.1
Q: オンライン視覚化にはデータを公開する必要がありますか?
A: はい。Hugging Face Spaces のオンライン視覚化ツールは公開されたデータセットのみにアクセスできます。機密情報が含まれる場合や非公開を維持する必要がある場合は、ローカルの Rerun SDK ソリューションを使用してください。
Q: データを Hugging Face にアップロードするにはどうすればよいですか?
A: 公式の CLI ツールを使用します:
# Hugging Face CLI のインストール
pip install -U huggingface_hub
# アカウントにログイン
huggingface-cli login
# (任意)データセットリポジトリの作成
huggingface-cli repo create your-username/dataset-name --type dataset
# データセットのアップロード(repo_type を dataset に指定)
huggingface-cli upload your-username/dataset-name /path/to/dataset --repo-type dataset --path-in-repo .
モデルトレーニング関連
Q: サポートされているモデルタイプは何ですか?
A: LeRobot 形式は、複数の主要な VLA モデルをサポートしています:
- smolVLA:単一GPU環境と迅速なプロトタイプ開発に適しています。
- Pi0:強力なマルチモーダル能力を持ち、複雑なタスクに適しています(OpenPI フレームワークに属します)。
- ACT:単一タスクの最適化に特化し、高いアクション予測精度を持ちます。
具体的にサポートされているモデルは、以下を参照してください:https://github.com/huggingface/lerobot/tree/main/src/lerobot/policies
Q: トレーニング中にメモリ不足(OOM)が発生した場合はどうすればよいですか?
A: 以下の最適化戦略を試してください:
- バッチサイズを減らす:
--batch_size 1またはそれ以下 - 混合精度トレーニングを有効にする:
--policy.use_amp true - データロードのスレッド数を減らす:
--num_workers 1 - 観測ステップ数を減らす:
--policy.n_obs_steps 1 - GPU キャ��ッシュをクリアする:トレーニングスクリプトに
torch.cuda.empty_cache()を追加
Q: 適切なモデルをどのように選択すればよいですか?
A: 具体的なニーズに応じて選択してください:
- 迅速なプロトタイプ開発:smolVLA を選択。
- 複雑なマルチモーダルタスク:Pi0 を選択(OpenPI フレームワークが必要)。
- リソースが限られた環境:smolVLA または ACT を選択。
- 単一の専門タスク:ACT を選択。
Q: トレーニング効果はどのように評価されますか?
A: LeRobot は複数の評価方法を提供しています:
- 定量指標:アクション誤差(MAE/MSE)、軌道類似度(DTW)。
- 定性評価:実機テストの成功率、行動分析。
- プラットフォーム評価:艾欧プラットフォームは視覚化されたモデル品質評価ツールを提供します。
Q: トレーニング時間はどのくらいかかりますか?
A: トレーニング時間は複数の要因に依存します:
- データ規模:50 個のデモンストレーションクリップで通常 2〜8 時間かかります。
- ハードウェア構成:A100 はコンシューマー向け GPU よりも 3〜5 倍高速です。
- モデル選択:smolVLA は ACT よりもトレーニング速度が速いです。
- トレーニング戦略:ファインチューニングはゼロからのトレーニングよりも 5〜10 倍高速です。
テクニカルサポート
Q: 技術的な問題が発生した場合、どのようにサポートを受けられますか?
A: 以下のチャネルを通じてサポートを受けることができます:
- LeRobot 公式ドキュメントを参照:https://huggingface.co/docs/lerobot
- GitHub で Issue を送信:https://github.com/huggingface/lerobot/issues
- 艾欧プラットフォームのテクニカルサポートチームに連絡
- LeRobot コミュニティの議論に参加
Q: 艾欧プラットフォームはモデルの自動デプロイをサポートしていますか?
A: はい。艾欧プラットフォームは、Pi0(OpenPI フレームワーク)、smolVLA、ACT などの主要モデルの自動デプロイサービスをサポートしています。詳細については、テクニカルサポートチームに連絡してデプロイ案と価格情報を入手してください。
関連リソース
公式リソース
- LeRobot Studio (艾欧オンライン視覚化): https://io-ai.tech/lerobot/
- LeRobot プロジェクトページ: https://github.com/huggingface/lerobot
- LeRobot モデルコレクション: https://huggingface.co/lerobot
- LeRobot 公式ドキュメント: https://huggingface.co/docs/lerobot
- Hugging Face オンライン視覚化ツール: https://huggingface.co/spaces/lerobot/visualize_dataset
ツールとフレームワーク
- Rerun 視覚化プラットフォーム: https://www.rerun.io/
- Hugging Face Hub: https://huggingface.co/docs/huggingface_hub
学術リソース
- Pi0 オリジナル論文: https://arxiv.org/abs/2410.24164
- ACT 論文: Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
- VLA レビュー論文: Vision-Language-Action Models for Robotic Manipulation
OpenPI 関連リソース
- OpenPI プロジェクトページ: https://github.com/Physical-Intelligence/openpi
- Physical Intelligence: https://www.physicalintelligence.company/
コミュニティリソース
- LeRobot GitHub Discussions: https://github.com/huggingface/lerobot/discussions
- Hugging Face ロボット学習コミュニティ: https://huggingface.co/spaces/lerobot
本文档は、LeRobot エコシステムの最新の発展とベストプラクティスを反映するために継続的に更新されます。ご質問やご提案がありましたら、艾欧プラットフォームのテクニカルサポートを通じてお問い合わせください。