モデル推論
訓練されたモデルは、実際のシナリオで使用するために推論サービスとしてデプロイする必要があります。従来のデプロイ方法では、環境設定、コード記述、ネットワーク通信の処理などが必要で、複雑でエラーが発生しやすいです。
プラットフォームは製品化された推論デプロイプロセスを提供します。コード記述は不要で、Webインターフェースを通じてモデルデプロイから本番アプリケーションまでの完全な操作を完了できます。モデルを選択し、パラメータを設定し、デプロイをクリックするだけです。
クイックスタート:3ステップで推論サービスをデプロイ
ステップ1:モデルを選択
ファインチューニングモデルを使用(推奨):
- 訓練タスクから完了したモデルを選択
- チェックポイントを選択(「last」または「best」を使用することを推奨)
- システムが自動的に訓練からモデル設定とパラメータを継承
- 追加設定は不要、直接デプロイ可能
その他のモデルソース:
- カスタムモデルをアップロード:SafeTensors、PyTorch(.pth、.pt)、ONNXなどの形式をサポート
- 事前訓練モデルを使用:モデルリポジトリから検証済みのベースモデルを選択、Pi0、SmolVLA、GR00Tなど
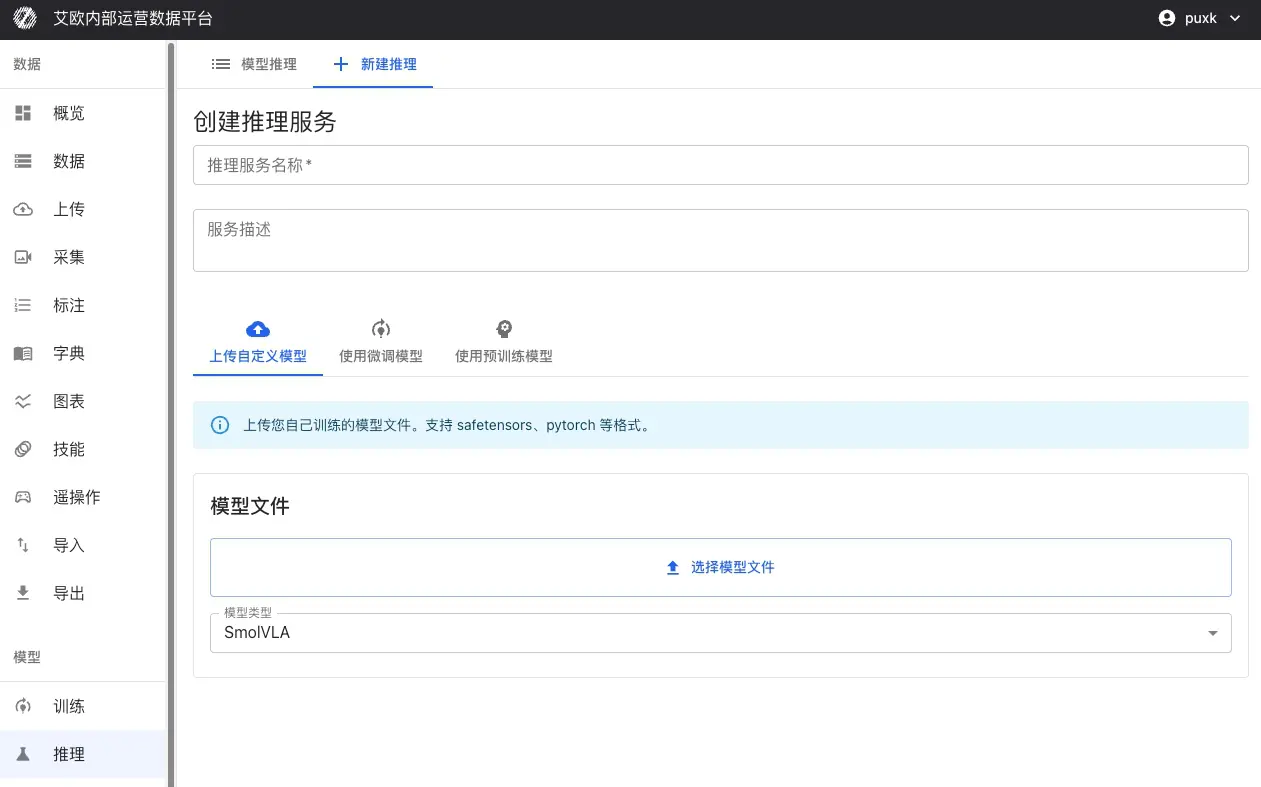
ステップ2:サービスを設定
基本情報:
- サービス名:推論サービスの識別しやすい名前を設定
- サービス説明:オプション、サービスの目的や説明を追加
- プロジェクト:サービスを特定のプロジェクトに関連付け、管理を容易に
- モデルタイプ:モデルタイプを選択、システムが自動的に適応
推論パラメータ:
- 推論精度:bfloat16またはfloat32を選択(速度と精度に影響)
- バッチサイズ:バッチ推論のバッチサイズ
- 最大シーケンス長:シーケンスをサポートするモデルについて、最大シーケンス長を制限
コンピューティングリソース:
- 利用可能なGPUリソースを自動検出
- 特定のGPUを選択またはマルチGPUデプロイをサポート
- CUDA、MPS(Apple Silicon)などのプラットフォームをサポート
- GPUがない場合はCPUに自動フォールバック(パフォーマンスは低い)
ステップ3:サービスをデプロイ
「デプロイ」ボタンをクリックした後:
- システムが自動的にDockerコンテナを作成
- モデル重みと設定をロード
- 推論サービスを起動(約20-30秒かかる)
- 自動的にヘルスチェックを実行し、サービスが正常であることを確認
デプロイ完了後、推論サービスは自動的に起動し、実行状態を維持し、すぐに推論テストを実行できます。
推論テスト方法
プラットフォームは3つの推論テスト方法を提供し、異なるシナリオのニーズを満たします:
| 推論方法 | 使用ケース | 説明 |
|---|---|---|
| シミュレーション推論テスト | 迅速な検証 | ランダムデータまたはカスタム入力を使用して、モデル推論機能とパフォーマンスを迅速に検証 |
| MCAPファイルテスト | 実データ検証 | 記録されたロボットデモデータを使用して、実際のシナリオでのモデル推論効果を検証 |
| オフラインエッジデプロイ | 本番環境アプリケーション | 推論サービスをロボットローカルGPUにデプロイし、低レイテンシのリアルタイム制御を実現 |
シミュレーション推論テスト
いつ使用するか?
- モデルサービスが正常に起動したかを迅速に検証
- モデルの入力/出力形式が正しいかをテスト
- 推論サービスの応答速度を評価
- 自然言語指示処理能力を検証
使用方法:
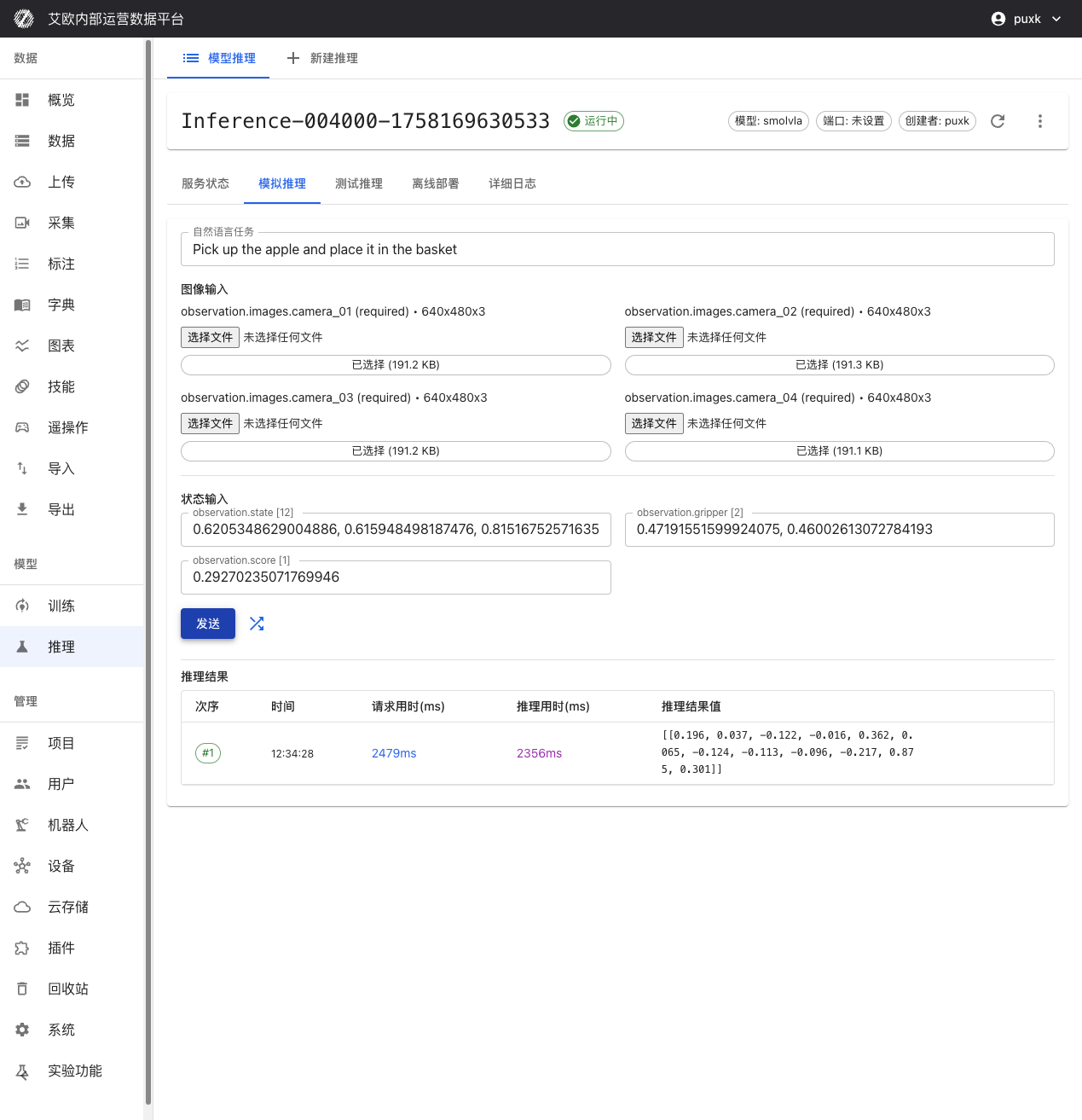
- 推論サービス詳細ページに移動し、「シミュレーション推論」タブに切り替え
- 自然言語タスク指示を入力、例:「リンゴを拾ってバスケットに入れる」
- 「ランダム入力」をクリックしてテストデータを自動生成、または手動でデータを入力
- 「送信」ボタンをクリック、すぐにモデル推論結果を取得
パフォーマンス指標:
- リクエスト時間:リクエスト送信から応答受信までの総時間(ネットワーク転送を含む)
- 推論時間:実際のモデル推論計算時間
- データ転送時間:データアップロードとダウンロード時間
これらの指標は、モデルパフォーマンスとシステムレイテンシを評価するのに役立ちます。
MCAPファイルテスト
いつ使用するか?
- 実際のシナリオでのモデルパフォーマンスを評価
- 推論結果とエキスパートデモを比較
- 完全なアクションシーケンスでのモデル効果を検証
- 最適なモデルチェックポイントを選択
使用方法:
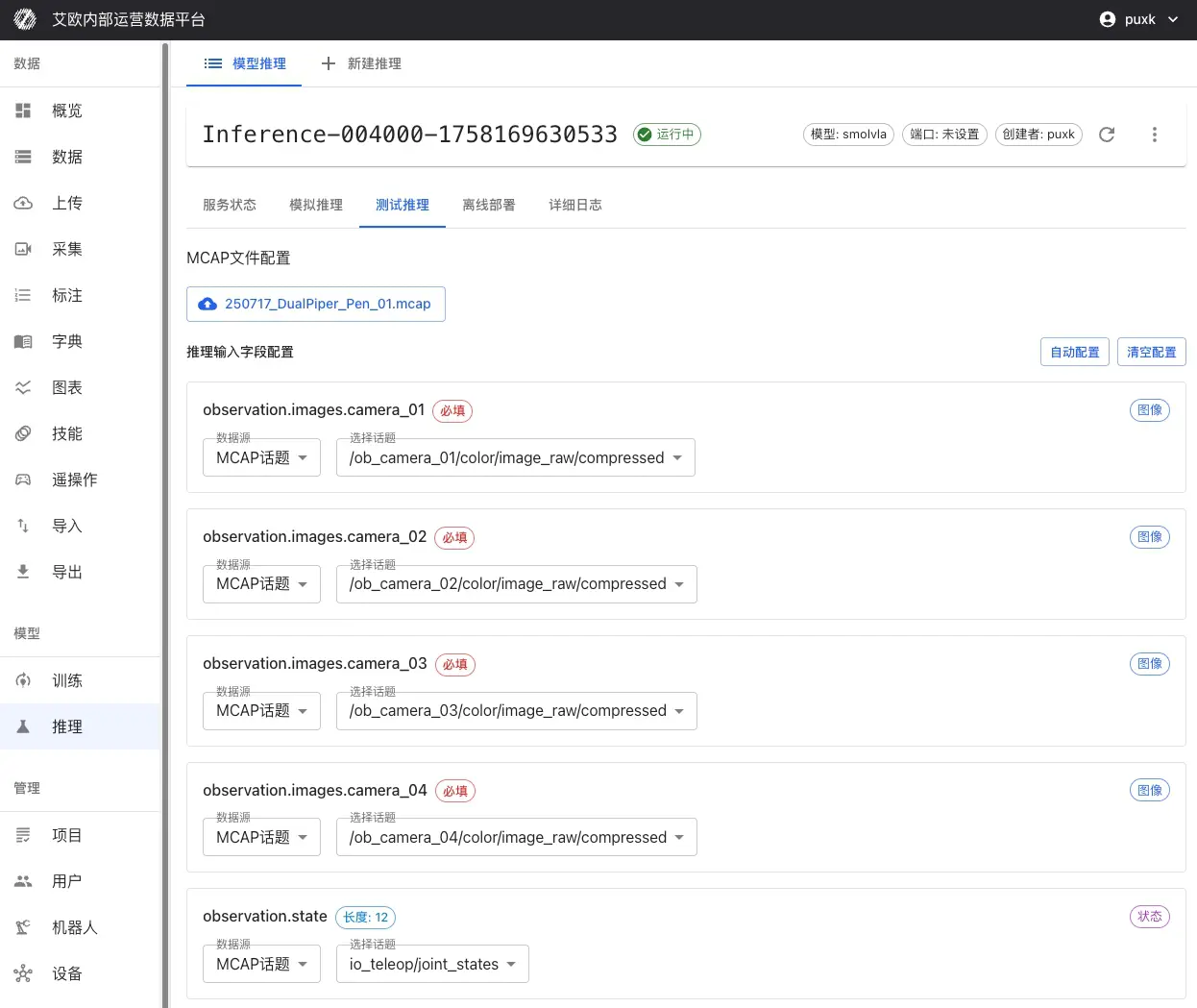
- 推論サービス詳細ページに移動し、「テスト推論」タブに切り替え
- MCAPファイルを選択:
- プラットフォームデータセットから直接選択
- またはMCAPファイルをローカルに�アップロード
- 入力マッピングを設定:
- MCAP内のどのカメラトピックがモデル入力にマッピングされるかを選択
- 関節状態、グリッパー状態などのデータのマッピングを設定
- シーケンス全体の自然言語タスク説明を設定
- 推論範囲を設定:
- 推論の開始フレームと終了フレームを選択
- 推論速度を向上させるために特定のフレームをスキップするように設定可能
- 推論を開始:「推論を開始」をクリック、システムが完全なシーケンスで連続推論を実行
効果比較分析:
推論完了後、システムは以下を提供します:
- アクション比較:推論されたアクションとエキスパートデモアクションの違いを比較
- 軌跡可視化:予測軌跡と実際の軌跡を可視化
- エラー統計:アクションエラー、位置エラーなどの統計指標を計算
- パフォーマンス評価:実データでのモデルパフォーマンスを評価
💡 推奨:訓練データと類似したシーンからのMCAPファイルを使用してテストし、アクションエラーと軌跡の一貫性に焦点を当てます。
オフラインエッジデプロイ
オフラインデプロイが必要な場合:
- 本番環境でのリアルタイムロボット制御
- ネットワークが不安定または制限された環境
- 極めて高いレイテンシ要件があるアプリケーションシナリオ
- データローカライゼーションが必要なセキュリティに敏感なシナリオ
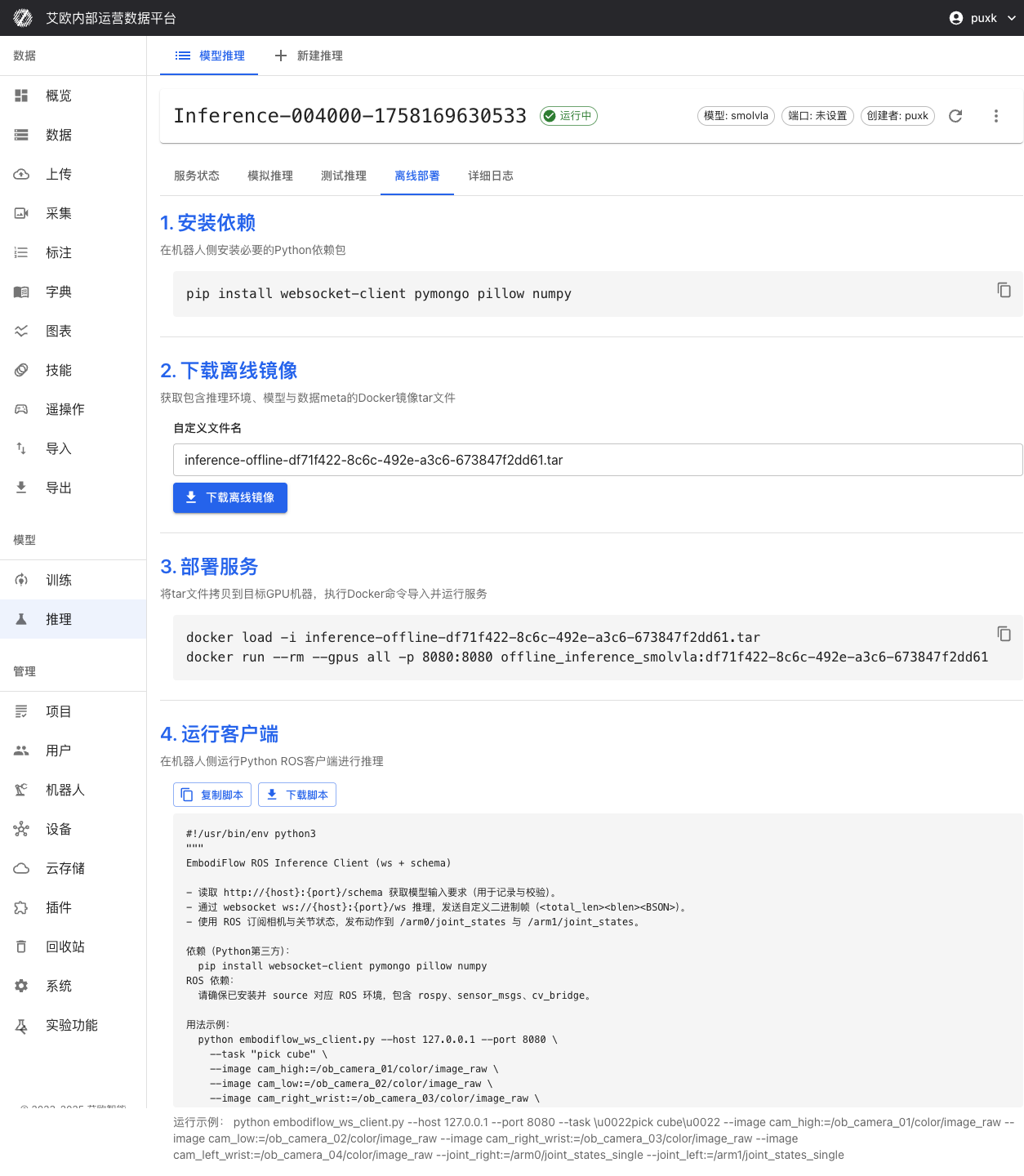
デプロイ手順:
-
環境準備:
- ロボットコントローラーにDockerとnvidia-docker2をインストール(GPUを使用する場合)
- Dockerイメージとモデルファイルをダウンロードするための十分なストレージスペースを確保
-
デプロイパッケージをダウンロード:
- 推論サービス詳細ページで「オフラインデプロイ」タブに切り替え
- 推論環境、モデル重み、設定を含む完全なDockerイメージをダウンロード
- モデル重みファイルと設定ファイルをダウンロード
-
サービスを起動:
- 提供されたDockerコマンドを使用してローカルで推論サービスを起動
- GPU加速をサポート(ハードウェアがサポートする場合)
- ポートとネットワークを自動設定
-
クライアント接続:
- プラットフォームが提供するROSクライアントスクリプトを実行
- 推論サービスとのリアルタイム通信を確立(WebSocket + BSONプロトコル)
- センサートピックを購読し、関節制御コマンドを発行
-
検証テスト:
- テストスクリプトを実行してサービスが正常であることを検証
- 推論レイテンシと精度を確認
- ROSトピックの購読と発行が正常であることを確認
オフラインデプロイの利点:
- 低レイテンシ:推論がロボットローカルで実行され、ネットワークレイテンシを完全に排除
- オフライン利用可能:外部ネットワーク接続に依存せず、オフライン環境での可用性を確保
- データセキュリティ:データがロボットローカルを離れず、データセキュリティ要件を満たす
- リアルタイム制御:高頻度推論(2-10Hz)をサポートし、リアルタイム制御ニーズを満たす
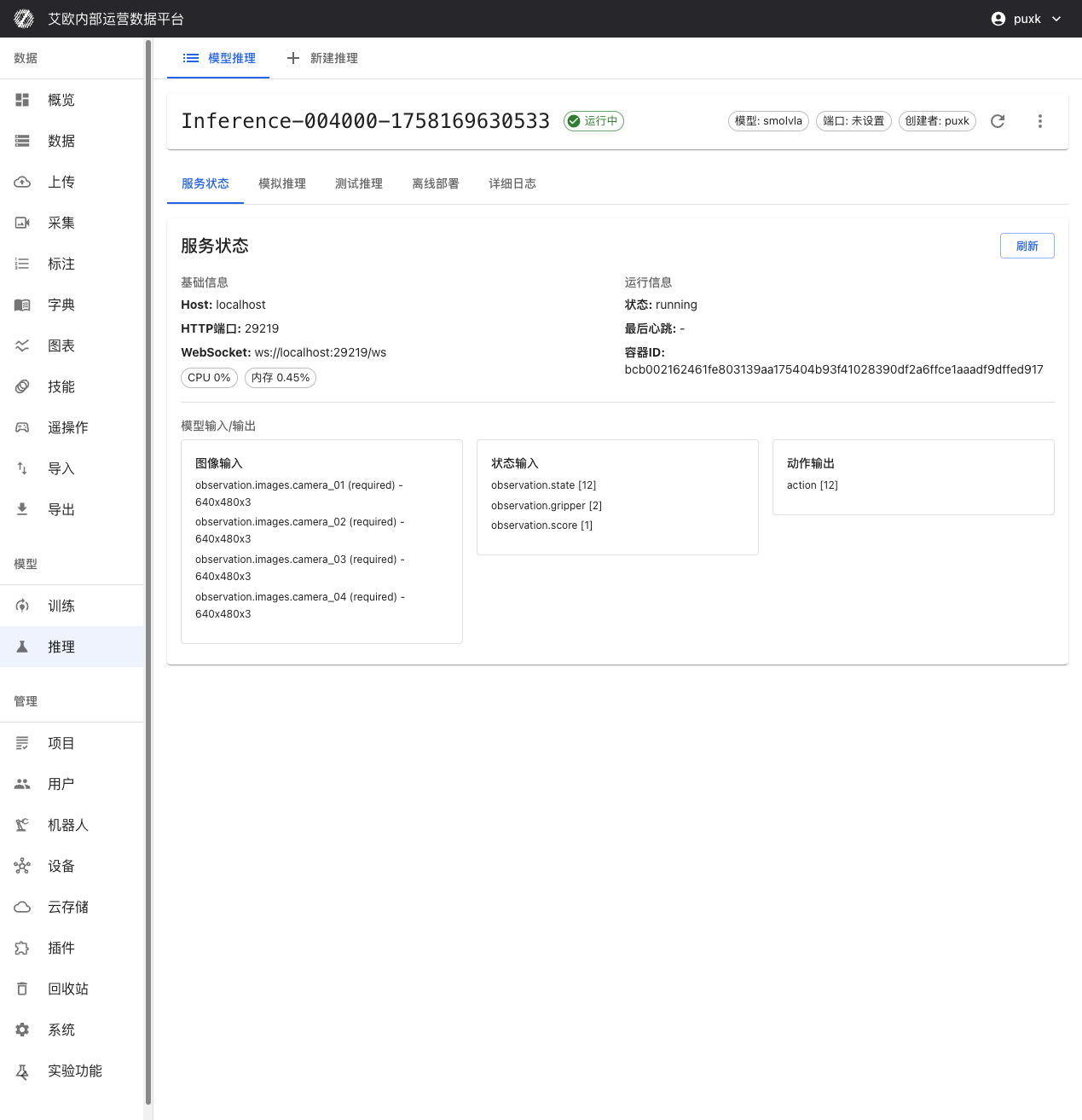
サービス管理
サービス状態を確認するには?
サービス情報:
推論サービス詳細ページで以下を確認できます:
- ホストアドレスとポート:推論APIのHTTPとWebSocketアクセスアドレス
- サービス状態:サービス実行状態のリアルタイム表示(実行中、停止、エラーなど)
- コンテナ情報:DockerコンテナIDと実行状態
- 作成時間:サービスの作成と最終更新時間
リソース監視:
- CPU使用率:CPU使用率のリアルタイム表示
- メモリ使用率:メモリ使用率とピークを表示
- GPU使用率:GPUを使用する場合、GPU利用率とメモリ使用率を表示
- ネットワークIO:ネットワークトラフィック統計を表示
サービスを制御するには?
サービス制御:
- 起動/停止:いつでも推論サービスを起動または停止可能
- サービス再起動:設定変更を適用するためにサービスを再起動
- サービス削除:不要な推論サービスを削除してリソースを解放
���💡 推奨:デプロイ後、サービスが完全に起動するまで20-30秒待つことを推奨します。長時間使用されていないサービスは停止してリソースを解放できます。
モデル入力/出力仕様
推論サービスはインテリジェントな適応能力を持ち、異なるモデルの入力/出力要件を自動的に識別し、適応できます:
入力:
- 画像入力:カメラ数(1または複数ビュー)と解像度(自動スケーリング)にインテリジェントに適応
- 状態入力:observation.state [12], observation.gripper [2], observation.score [1]
出力:
- アクション出力:action [12] ロボット関節制御コマンド
システムが自動的にデータ形式変換を処理するため、モデル要件に従ってデータを提供するだけです。
推論クォータ管理
推論クォータとは?
推論クォータは、リソース使用を制御し、システムリソースの合理的な配分を確保するために使用されます。
クォータタイプ:
- ユーザークォータ:各ユーザーは独立した推論クォータ制限を持つ
- グローバルクォータ:システムレベルの総クォータ制限(管理者が設定)
- クォータ統計:使用済みクォータと残りクォータのリアルタイム表示
クォータ表示:
- 推論ページに現在のユーザーのクォータ使用状況を表示
- 使用済み数と総クォータ制限を表示
- クォータを超過すると新しい推論サービスを作成できない
クォータ管理(管理者):
管理者は以下を実行できます:
- すべてのユーザーの推論クォータ使用状況を確認
- グローバル推論クォータ制限を設定
- 個別ユーザークォータを調整
よくある質問
適切なモデルを選択するには?
選択推奨事項:
- ファインチューニングモデルを使用:最初のデプロイでは、モデルが訓練データと一致することを確保するためにファ�インチューニングモデルを使用することを推奨
- 迅速なテスト:迅速なテストが必要な場合、事前訓練モデルを使用可能
- カスタムモデル:カスタムモデルは形式互換性と設定の正確性を確保する必要がある
推論サービスが起動に失敗した場合はどうすればよいか?
考えられる原因:
- GPUリソース不足:GPUが他のサービスによって占有されているかどうかを確認
- モデルファイルエラー:モデルファイルが完全で形式が正しいかどうかを確認
- 設定エラー:推論パラメータ設定が合理的かどうかを確認
- コンテナ起動失敗:詳細ログを確認して具体的なエラーを理解
解決方法:
- サービスログを確認して失敗理由を理解
- エラー情報に基づいて問題を修正
- サービスを再デプロイ
推論速度を向上させるには?
最適化推奨事項:
- GPUを使用:GPU推論はCPUよりはるかに高速
- 精度を下げる:bfloat16を使用すると速度を向上できるが、精度がわずかに低下する可能性がある
- バッチサイズを調整:実際の状況に基づいてバッチサイズを調整
- オフラインデプロイを使用:ローカル推論はネットワークレイテンシを排除できる
推論結果を検証するには?
検証方法:
- シミュレーション推論:ランダムデータを使用してサービスが正常であるかを迅速に検証
- MCAPテスト:実データを使用してモデル効果を検証
- 比較分析:推論結果とエキスパートデモを比較
- 実際のテスト:実際のロボットで推論効果をテスト
関連機能
推論サービスデプロイを完了した後、以下も必要になる場合があります:
- モデル訓練:新しいモデルを訓練
- アクションリターゲティング:アクションを異なるロボットに適応
- データエクスポート:より多くの訓練データをエクスポート