LeRobot 数据集
LeRobot 是 Hugging Face 开源的机器人学习数据标准化框架,专为机器人学习与强化学习场景设计。它提供统一的数据格式规范,便于研究人员共享、对比与复现实验,显著降低不同项目之间的数据格式转换成本。
导出数据
整体流程可概括为:从已标注数据到模型训练。选择导出格式并配置参数 → 导出后下载解压 → 即可用于 LeRobot 或 OpenPI 等框架,训练 Pi0、SmolVLA、ACT、Diffusion 等模型。
艾欧数据平台支持按 LeRobot 标准格式导出数据,可直接用于 VLA(Vision-Language-Action)模型的训练。导出的数据包含完整的感知-理解-执行闭环:视觉感知、自然语言指令与对应动作序列的多模态映射。
LeRobot 格式导出对计算资源要求较高。艾欧数据开放平台在免费版中对每位用户的导出次数做了合理限制;付费版支持无限制导出,并配备 GPU 加速,可明显缩短导出时间。
1. 选择要导出的数据
导出前需先完成标注。标注会将机器人的动作序列与自然语言指令建立精确映射,是训练 VLA 模型的必要前提;模型借此学习将语言指令转化为机器人控制动作。
数据标注的详细流程与批量标注技巧,请参阅:数据标注指南
标注完成后,在导出界面可查看所有已标注数据集。支持按需选择数据子集,只导出所需部分。
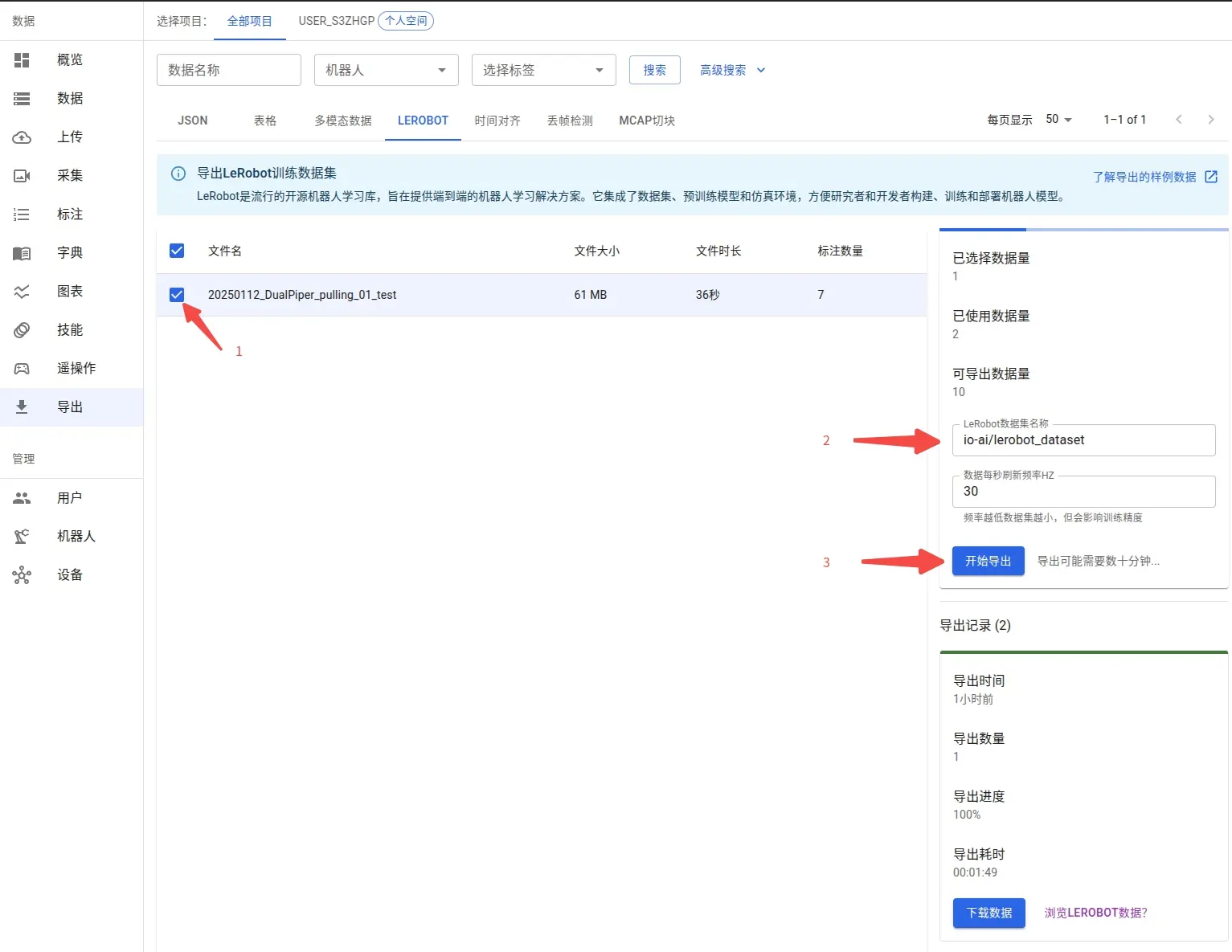
数据集名称可自定义。若计划将数据集发布到 Hugging Face,建议采用标准仓库命名(如 myproject/myrepo1),便于后续分享与协作。
导出配置选项
在导出界面右侧的配置面板中可设置以下参数:
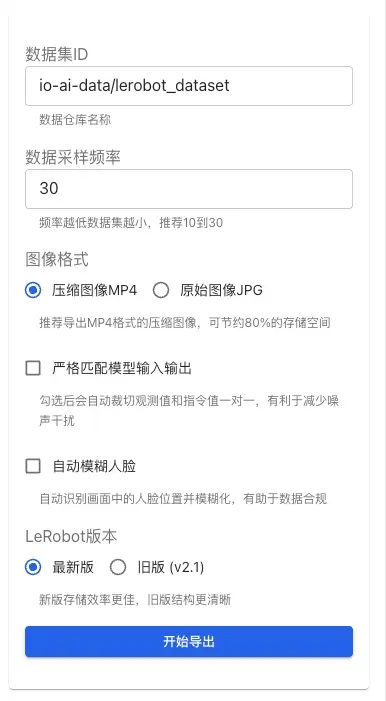
数据采样频率:控制采样频率(推荐 10–30 Hz)。频率越低,数据集体积越小,但可能丢失部分细节。
图像格式:
- MP4(推荐):压缩格式,约可节省 80% 存储,适合大规模导出
- JPG:原始画质,文件体积较大
严格匹配模型输入输出:开启后会自动裁切观测与指令,保证一一对应,有助于减少噪声、提升训练质量。
自动模糊人脸:开启后会自动检测并模糊画面中的人脸,用于:
- 保护隐私、满足数据合规
- 适用于含操作人员画面的数据集
- 对所有导出图像中的人脸统一处理
数据量越大,导出耗时越长。建议按任务类型分批导出,避免一次处理全部数据。分批导出既有利于速度,也便于后续管理、版本控制和针对性训练。
2. 下载与解压导出文件
导出耗时取决于数据规模和系统负载,通常为数十分钟。页面会自动更新进度,可稍后返回查看。
完成后,在页面右侧 导出记录 中点击 下载数据,将得到 .tar.gz 压缩包。

建议在本地建一个专用目录(如 ~/Downloads/mylerobot3)再解压,避免与其他数据混在一起。

解压后的目录符合 LeRobot 标准格式,包含完整多模态数据:视觉观测、机器人状态与动作标签等。

3. 自定义 Topic 映射
导出 LeRobot 数据时,需要把 ROS/ROS2 的 Topic 映射到 LeRobot 的观测(observation.state)与动作(action)字段。了解映射规则有助于正确导出自定义数据集。
默认 Topic 映射规则
平台按话题名称后缀自动识别:
观测(observation.state)
- 话题名以
/joint_state或/joint_states结尾时,其position会被识别为观测并写入observation.state - 例如:
io_teleop/joint_states、/arm/joint_state
动作(action)
- 话题名以
/joint_cmd或/joint_command结尾时,其position会被识别为动作并写入action - 例如:
io_teleop/joint_cmd、/arm/joint_command
录制数据时建议遵循上述命名。若现有话题命名不同,可联系技术支持做适配。
自定义 Topic 支持
若使用自定义话题且命名不符合默认规则,可以:
- 重命名话题:在录制阶段将话题改为符合默认规则的名称(如
/joint_states、/joint_command)。 - 联系技术支持:无法改名的,可联系艾欧平台技术支持,按您的命名习惯做适配,保证正确映射到 LeRobot 格式。
当前版本暂不支持在导出界面直接配置自定义话题映射。若有特殊需求,建议提前与技术支持沟通,以便在�导出前完成配置适配。
数据可视化与验证
为便于快速理解与校验数据内容,LeRobot 支持多种可视化方式。下表按使用场景对比,艾欧数据平台推荐优先使用 LeRobot Studio:
| 使用场景 | 方案 | 特点 |
|---|---|---|
| 快速隐私预览(推荐) | LeRobot Studio(Web) | 免安装、免上传、保护隐私、即拖即用;含「数据集健康」面板做格式校验 |
| 本地开发调试 | Rerun SDK 本地查看 | 功能完整、交互强、可离线 |
| 公开分享展示 | Hugging Face 在线查看 | 便于协作与分享、随时访问 |
1. 使用 LeRobot Studio 在线可视化(推荐)
艾欧数据平台集成了 LeRobot Studio,用于 LeRobot 数据的在线可视化。无需安装本地环境,也无需将数据上传到 Hugging Face,在浏览器中即可完成本地数据的查看与校验。
体验地址:https://io-ai.tech/lerobot/
核心优势
- 零门槛:无需配置 Python 或安装 Rerun SDK
- 隐私安全:支持本地文件拖拽预览,数据不经过云端
- 功能完整:支持 LeRobot 多模态回放(图像、状态、动作)
- 数据集健康:加载后在侧边栏提供「数据集健康」面板,自动进行 v2.1/v3.0 格式校验(文件结构、
meta/info、features、episode 数量与 length 等),便于导出后快速确认数据是否完整、是否符合 LeRobot 规范 - 无缝集成:与艾欧数据平台的导出与可视化流程打通,随时可用
使用方法
- 打开 LeRobot Studio
- 点击 「选择文件」 或将导出的
.tar.gz(或解压后的文件夹)拖入窗口 - 解析完成后即可进行交互式回放
2. 使用 Rerun SDK 本地可视化
在本地安装 lerobot 后,可使用 LeRobot 提供的 lerobot-dataset-viz 命令(对应 lerobot.scripts.lerobot_dataset_viz)配合 Rerun SDK 做时间轴式的多模态可视化,同时展示图像、状态、动作等,交互与自定义能力最强。
环境与依赖
建议 Python 3.10+,然后执行:
# 安装 Rerun SDK
python3 -m pip install rerun-sdk==0.23.1
# 克隆 LeRobot 官方仓库
git clone https://github.com/huggingface/lerobot.git
cd lerobot
# 安装 LeRobot 开发环境
pip install -e .
启动数据可视化
lerobot-dataset-viz \
--repo-id local/mylerobot3 \
--root ~/Downloads/mylerobot3 \
--episode-index 0
参数说明:
--repo-id:Hugging Face 数据集标识或本地占位符(如io-ai-data/lerobot_dataset、local/mylerobot3)--root:本地 LeRobot 数据集根目录(包含meta/info.json、data/、videos/等的路径);从 Hub 加载时可省略--episode-index:要可视化的 episode 索引(从 0 开始)
保存为离线文件
可将结果保存为 Rerun 文件(.rrd),便于离线查看或分享:
lerobot-dataset-viz \
--repo-id local/mylerobot3 \
--root ~/Downloads/mylerobot3 \
--episode-index 0 \
--save 1 \
--output-dir ./rrd_out
# 离线查看保存的可视化文件(文件名以脚本输出为准,如 lerobot_<repo_id>_episode_<index>.rrd)
rerun ./rrd_out/lerobot_local_mylerobot3_episode_0.rrd
远程可视化(gRPC 流式)
在远程服务器上处理数据、在本地查看时,可使用流式模式。官方已弃用 --ws-port,请使用 --grpc-port(默认 9876):
# 在服务器端启动可视化服务
lerobot-dataset-viz \
--repo-id local/mylerobot3 \
--root /path/to/dataset \
--episode-index 0 \
--mode distant \
--grpc-port 9876
# 在本地连接(将 服务器IP 替换为实际 IP)
rerun rerun+http://服务器IP:9876/proxy
3. 使用 Hugging Face Spaces 在线可视化
若不想安装本地环境,可使用 LeRobot 在 Hugging Face Spaces 上的在线可视化工具,无需本地依赖,适合快速预览或团队分享。
在线可视化需将数据上传到 Hugging Face。免费账户仅支持公开仓库的可视化,数据会公开可见。若数据敏感需保密,请使用本地可视化方案。
操作步骤
- 打开 在线可视化工具
- 在 Dataset Repo ID 中填入数据集标识(如
io-intelligence/piper_uncap_pen) - 在左侧选择要查看的 Episode(如 Episode 0)
- 使用顶部播放控制选择查看方式
模型训练指南
基于 LeRobot 数据的模型训练��,关键不在于把所有框架都试一遍,而在于尽快选定一条与目标模型匹配的训练链路。对于网站访客而言,最直接的方式通常是先使用已经准备好的训练镜像,把数据挂载进去,先跑通再调参。
下文与专项指南中的示例默认使用 Docker Hub 上的 ioaitech/... 镜像名。若你在中国大陆访问 Docker Hub 较慢,可使用华为云容器镜像服务同步地址,将前缀替换为 swr.cn-east-3.myhuaweicloud.com/ioaitech/,例如:
swr.cn-east-3.myhuaweicloud.com/ioaitech/train_act:cudaswr.cn-east-3.myhuaweicloud.com/ioaitech/train_openpi:pi0swr.cn-east-3.myhuaweicloud.com/ioaitech/train_openpi:pi05docker run的挂载路径与训练参数保持不变。
模型选择策略
常见 VLA 模型对比如下:
| 模型类型 | 适用场景 | 特点 | 推荐用途 |
|---|---|---|---|
| smolVLA | 单卡、快速原型 | 参数量适中、训练快 | 消费级 GPU、概念验证 |
| Pi0 / Pi0.5 | 复杂任务、多模态 | 使用 OpenPI 官方训练链路,适合高质量微调 | 复杂交互、对泛化要求较高的任务 |
| ACT | 单任务优化 | 训练链路直接、镜像即开即用 | 特定任务、高频控制 |
| Diffusion | 平滑动作生成 | 扩散模型、轨迹顺滑 | 需要平滑轨迹的任务 |
| VQ-BeT | 动作离散化 | 向量量化、推理快 | 实时控制 |
| TDMPC | 模型预测控制 | 样本效率高、可在线学习 | 数据较少场景 |
Pi0 / Pi0.5 建议优先使用 OpenPI 微调链路与下列已发布镜像:
ioaitech/train_openpi:pi0ioaitech/train_openpi:pi05- 对应的一键微调命令与参数说明见:Pi0 与 Pi0.5 模型微调指南
smolVLA 训练详解(推荐入门)
smolVLA 面向单卡/消费级环境,参数规模适中。强烈建议在官方预训练权重上微调,可大幅缩短训练时间并提升效果。
LeRobot 训练命令采用如下格式:
- 策略类型:
--policy.type smolvla - 参数:空格分隔,如
--batch_size 64(不要用=) - 布尔:
true/false,如--save_checkpoint true - 列表:空格分隔,如
--policy.down_dims 512 1024 2048 - 模型上传:默认可加
--policy.push_to_hub false关闭自动上传 HuggingFace Hub
环境准备
# 克隆 LeRobot 仓库
git clone https://github.com/huggingface/lerobot.git
cd lerobot
# 安装支持 smolVLA 的完整环境
pip install -e ".[smolvla]"
数据版本与 tag 对应(重要)
数据集中 meta/info.json 的 codebase_version 需与训练所用 LeRobot 代码 tag 一致:
| 数据集版本 | 推荐 LeRobot 代码版本 | 说明 |
|---|---|---|
v2.1 | v0.3.x | 旧版 dataset 结构,很多旧流程仍沿用 |
v3.0 | v0.4+(含 v0.5.x) | 新版 dataset 结构;截至 lerobot v0.5.0 仍然是 v3.0 |
推荐先执行对应 tag 再安装:
# v2.1 数据集
git checkout v0.3.3
pip install -e ".[all]"
# v3.0 数据集
git checkout v0.5.0
pip install -e ".[all]"
这里要注意区分两层版本:
v2.1/v3.0是 LeRobotDataset 格式版本v0.4.0/v0.5.0是 lerobot 代码库版本
截至 lerobot v0.5.0,数据格式主线仍然是 LeRobotDataset v3.0。若希望统一使用新版训练与数据工具,可以先将 v2.1 数据转换为 v3.0 再训练。
微调训练(推荐方案)
- 推荐本地数据集:数据体积大时,建议直接使用本地解压目录。
--dataset.repo_id local/xxx--dataset.root /path/to/dataset(目录下应包含meta/info.json、data/、meta/episodes/等)
- 已上传 Hugging Face Hub:可只设
--dataset.repo_id your-name/your-repo,去掉--dataset.root。
本地数据集微调示例(默认推荐)
# 例:你的数据放在本地目录(包含 meta/info.json, data/ 等)
DATASET_ROOT=~/Downloads/mylerobot3
lerobot-train \
--policy.type smolvla \
--policy.pretrained_path lerobot/smolvla_base \
--dataset.repo_id local/mylerobot3 \
--dataset.root ${DATASET_ROOT} \
--output_dir /data/lerobot_smolvla_finetune \
--batch_size 64 \
--steps 20000 \
--policy.optimizer_lr 1e-4 \
--policy.device cuda \
--policy.push_to_hub false \
--save_checkpoint true \
--save_freq 5000
实践建议:
- 数据:建议 50+ 个任务片段,覆盖不同物体位姿与环境
- 资源:单卡 A100 约 20k 步/4 小时;消费级卡可减小 batch_size 或开梯度累积
- 超参:从
batch_size=64、steps=20k、学习率1e-4起步 - 从零训练:仅在有大规模数据(数千小时级)时考虑
从零开始训练(高级用户)
# 从零训练(本地数据集示例)
DATASET_ROOT=~/Downloads/mylerobot3
lerobot-train \
--policy.type smolvla \
--dataset.repo_id local/mylerobot3 \
--dataset.root ${DATASET_ROOT} \
--output_dir /data/lerobot_smolvla_fromscratch \
--batch_size 64 \
--steps 200000 \
--policy.optimizer_lr 1e-4 \
--policy.device cuda \
--policy.push_to_hub false \
--save_checkpoint true \
--save_freq 10000
性能优化技巧
显存优化:
# 添加以下参数来优化显存使用
--policy.use_amp true \
--num_workers 2 \
--batch_size 32 # 减小批次大小
训练监控:
- 配置 Weights & Biases (W&B) 来监控训练曲线和评估指标
- 设置合理的验证间隔和早停策略
- 定期保存检查点以防训练中断
ACT 模型训练指南
ACT(Action Chunking Transformer)面向单任务或短时序策略学习。若你已经有结构清晰的 LeRobot 数据,并希望用尽量直接的方式完成训练,推荐优先使用已经发布的镜像 ioaitech/train_act:cuda。
ACT 要求 policy.n_action_steps ≤ policy.chunk_size。建议将两者设为相同值(如 100),避免配置错误。
数据预处理要求
轨迹与数据:
- 片段长度与时间对齐一致(推荐 10–20 步的 action chunk)
- 动作做归一化,统一尺度与单位
- 观测一致,尤其相机内参与视角
训练配置:
一键开始训练
docker run --rm --gpus all \
-v /path/to/lerobot_dataset:/data/input \
-v /path/to/output:/data/output \
ioaitech/train_act:cuda \
--run_name act_demo \
--task_name demo_task \
--num_epochs 12000 \
--batch_size 64 \
--learning_rate 5e-5 \
--chunk_size 100 \
--kl_weight 10
更完整的参数说明、输出目录和排错建议见:ACT 模型训练指南
性能调优策略
过拟合:增加数据多样性、适当正则、早停。
欠拟合:延长步数、调整学习率与调度、检查数据质量与一致性。
常见问题(FAQ)
数据导出
Q: 导出大概要多久?
A: 主要看数据量和系统负载,一般每 GB 约 3–5 分钟。建议按任务类型分批导出。
Q: 免费版导出有什么限制?
A: 免费版对每用户导出次数和频率有限制,具体以导出页为准。需要大量导出可考虑付费版(无限制 + GPU 加速)。
Q: 如何检查导出数据是否完整?
A: 推荐以下两种方式(官方仓库当前没有独立的 validate_dataset CLI):
- 推荐:使用 LeRobot Studio 打开导出的数据集(拖入
.tar.gz或解压后的文件夹),在侧边栏「数据集健康」面板查看格式校验结果(v2.1/v3.0 文件结构、meta/info.json、features、episodes 等);若有错误或警告会直接列出,便于确认导出是否完整。 - 可选(本地 Python):安装
lerobot后,用LeRobotDataset加载本地目录,若数据不完整或格式错误会抛出异常,可作为脚本化校验手段:
from lerobot.datasets import LeRobotDataset
ds = LeRobotDataset("local/myrepo", root="/path/to/解压后的数据集目录")
# 能加载成功即说明 meta/data 结构可被识别
Q: 导出的数据集太大怎么办?
A: 可尝试:降低采样频率(如 30fps→10–15fps);按时间段或任务拆分导出;在保证效果前提下适当压缩图像。
数据可视化
Q: Rerun SDK 安装失败?
A: 检查:Python ≥ 3.10;网络稳定;可尝试在虚拟环境中安装;或使用清华源:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple rerun-sdk==0.23.1
Q: 在线可视化是否必须公开数据?
A: 是。Hugging Face Spaces 在线工具只能访问公开数据集。若数据敏感需保密,请用艾欧提供的 LeRobot Studio 或者 LeRobot 官方的本地 Rerun 方案。
Q: 如何把数据上传到 Hugging Face?
A: 使用官方 CLI:
# 安装 Hugging Face CLI
pip install -U huggingface_hub
# 登录账户
huggingface-cli login
# (可选)创建一个 dataset 仓库
huggingface-cli repo create your-username/dataset-name --type dataset
# 上传数据集(repo_type 指定为 dataset)
huggingface-cli upload your-username/dataset-name /path/to/dataset --repo-type dataset --path-in-repo .
模型训练
Q: 支持哪些模型?
A: LeRobot 格式支持多种 VLA 模型:smolVLA(单卡/快速原型)、Pi0 / Pi0.5(复杂任务、多模态,推荐通过 OpenPI 镜像微调)、ACT(单任务、动作预测准,推荐通过 ioaitech/train_act:cuda 训练)。各模型入口见对应指南。
Q: Pi0 报错 AttributeError: 'GemmaForCausalLM' object has no attribute 'embed_tokens' 或 'layers'?
A: 这是使用 lerobot 旧版 Pi0 实现时常见的兼容性问题。当前文档推荐直接使用 ioaitech/train_openpi:pi0 或 ioaitech/train_openpi:pi05,绕开这类手工补丁路径。对应的一键命令见 Pi0 与 Pi0.5 模型微调指南。
Q: Pi0(v3 数据 + lerobot v0.4.3)报 ValueError: An incorrect transformer version is used?
A: 这同样属于 lerobot 旧版 Pi0 路径的兼容性问题。若你只是希望稳定微调并复现结果,建议直接走 OpenPI 镜像链路,而不是从这些历史依赖问题入手排查。
Q: 训练时显存不足?
A: 可尝试:减小 --batch_size(如 1);开启 --policy.use_amp true;减少 --num_workers;减少 --policy.n_obs_steps;在脚本中调用 torch.cuda.empty_cache()。
Q: 怎么选模型?
A: 快速原型 → smolVLA;复杂多模态 → Pi0 / Pi0.5;资源有限且先求稳 → ACT;单一专门任务 → ACT。
Q: 如何评估训练效果?
A: 定量:动作误差(MAE/MSE)、轨迹相似度(DTW)。定性:实机成功率、行为分析。艾欧平台也提供可视化评估工具。
Q: 训练大概要多久?
A: 受数据规模、硬件、模型与策略影响。例如:约 50 个演示片段约 2–8 小时;A100 比消费级卡快数倍;微调比从零训练快很多。
技术支持
Q: 遇到技术问题怎么获取帮助?
A: 可查阅 LeRobot 官方文档、在 GitHub 提 Issue、联系艾欧平台技术支持,或参与 LeRobot 社区讨论。
Q: 艾欧平台是否支持模型自动部署?
A: 支持。艾欧平台支持 Pi0(OpenPI)、smolVLA、ACT 等模型的自动部署,详情与定价可联系技术支持。
相关资源
官方资源
- LeRobot Studio (艾欧在线可视化): https://io-ai.tech/lerobot/
- LeRobot 项目主页: https://github.com/huggingface/lerobot
- LeRobot 模型集合: https://huggingface.co/lerobot
- LeRobot 官方文档: https://huggingface.co/docs/lerobot
- Hugging Face 在线可视化工具: https://huggingface.co/spaces/lerobot/visualize_dataset
工具和框架
- Rerun 可视化平台: https://www.rerun.io/
- Hugging Face Hub: https://huggingface.co/docs/huggingface_hub
学术资源
- Pi0 原始论文: https://arxiv.org/abs/2410.24164
- ACT 论文: Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
- VLA 综述论文: Vision-Language-Action Models for Robotic Manipulation
OpenPI 相关资源
- OpenPI 项目主页: https://github.com/Physical-Intelligence/openpi
- Physical Intelligence: https://www.physicalintelligence.company/
社区资源
- LeRobot GitHub Discussions: https://github.com/huggingface/lerobot/discussions
- Hugging Face 机器人学习社区: https://huggingface.co/spaces/lerobot
文档会随 LeRobot 生态更新而修订。如有疑问或建议,欢迎通过艾欧平台技术支持与我们联系。