模型推理
训练完成的模型需要部署为推理服务,才能在实际场景中使用。传统的部署方式需要配置环境、编写代码、处理网络通信等,过程复杂且容易出错。
平台提供了产品化的推理部署流程,无需编写代码,通过网页界面就能完成从模型部署到生产应用的完整操作。你只需要选择模型、配置参数,然后点击部署。
快速上手:3 步部署推理服务
第 1 步:选择模型
使用微调模型(推荐):
- 从训练任务中选择已完成的模型
- 选择检查点(推荐使用"last"或"best")
- 系统自动继承训练时的模型配置和参数
- 无需额外配置,可直接部署
其他模型来源:
- 上传自定义模型:支持 SafeTensors、PyTorch(.pth、.pt)、ONNX 等格式
- 使用预训练模型:从模型仓库选择经过验证的基础模型,如 Pi0、SmolVLA、GR00T 等
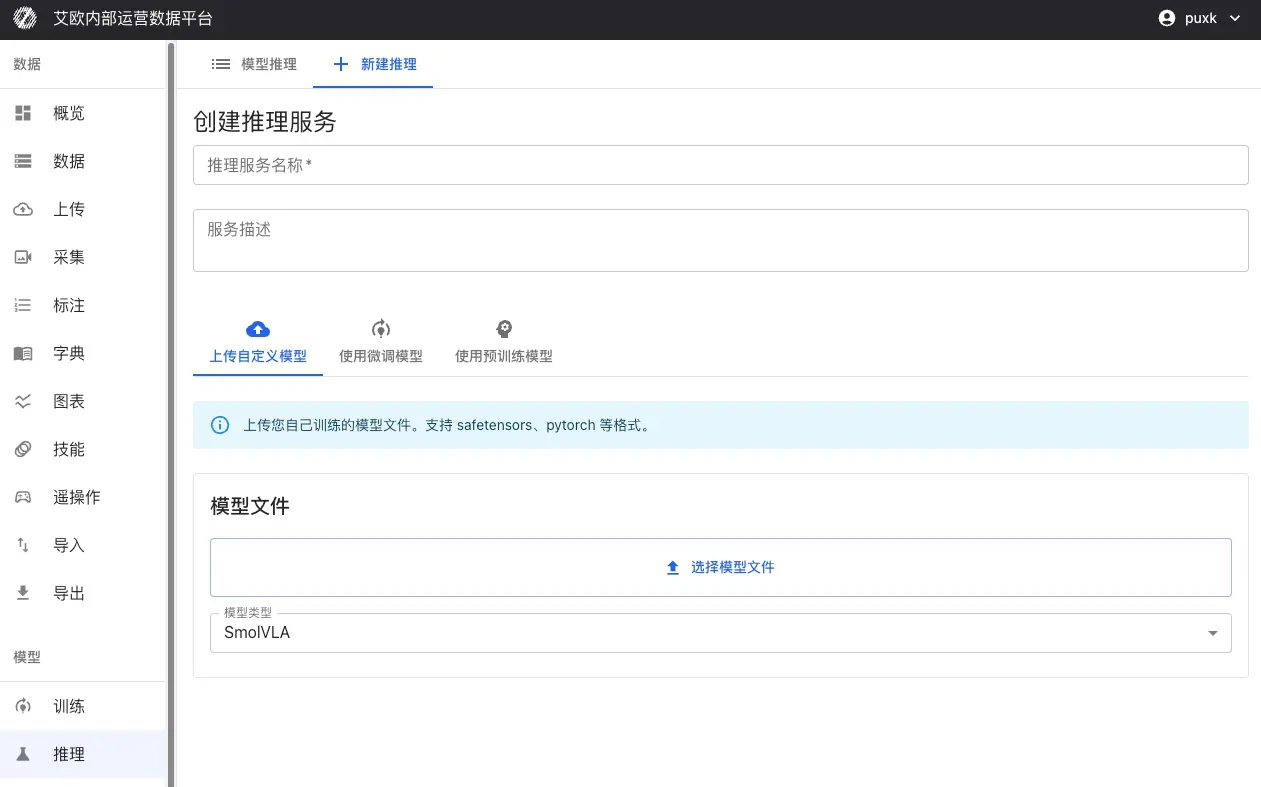
第 2 步:配置服务
基本信息:
- 服务名称:为推理服务设置一个易于识别的名称
- 服务描述:可选,添加服务用途或说明信息
- 所属项目:将服务关联到特定项目,便于管理
- 模型类型:选择模型的类型,系统会自动适配
推理参数:
- 推理精度:选择 bfloat16 或 float32(影响速度和精度)
- 批次大小:批量推理时的批次大小
- 最大序列长度:对于支持序列的模型,限制最大序列长度
计算资源:
- 自动检测可用的 GPU 资源
- 支持选择特定 GPU 或多 GPU 部署
- 支持 CUDA、MPS(Apple Silicon)等平台
- 无 GPU 时自动回退到 CPU(性能较低)
第 3 步:部署服务
点击"部署"按钮后:
- 系统自动创建 Docker 容器
- 加载模型权重和配置
- 启动推理服务(约需 20-30 秒)
- 自动进行健康检查,确保服务正常
部署完成后,推理服务将自动启动并保持运行状态,可以立即进行推理测试。
推理测试方式
平台提供三种推理测试方式,满足不同场景的需求:
| 推理方式 | 适用场景 | 说明 |
|---|---|---|
| 模拟推理测试 | 快速验证 | 使用随机数据或自定义输入,快速验证模型推理功能和性能 |
| MCAP 文件测试 | 真实数据验证 | 使用录制好的机器人演示数据,验证模型在真实场景下的推理效果 |
| 离线边缘部署 | 生产环境应用 | 将推理服务部署到机器人本地 GPU,实现低延迟的实时控制 |
模拟推理测试
什么时候使用?
- 快速验证模型服务是否正常启动
- 测试模型的输入输出格式是否正确
- 评估推理服务的响应速度
- 验证自然语言指令的处理能力
如何使用?
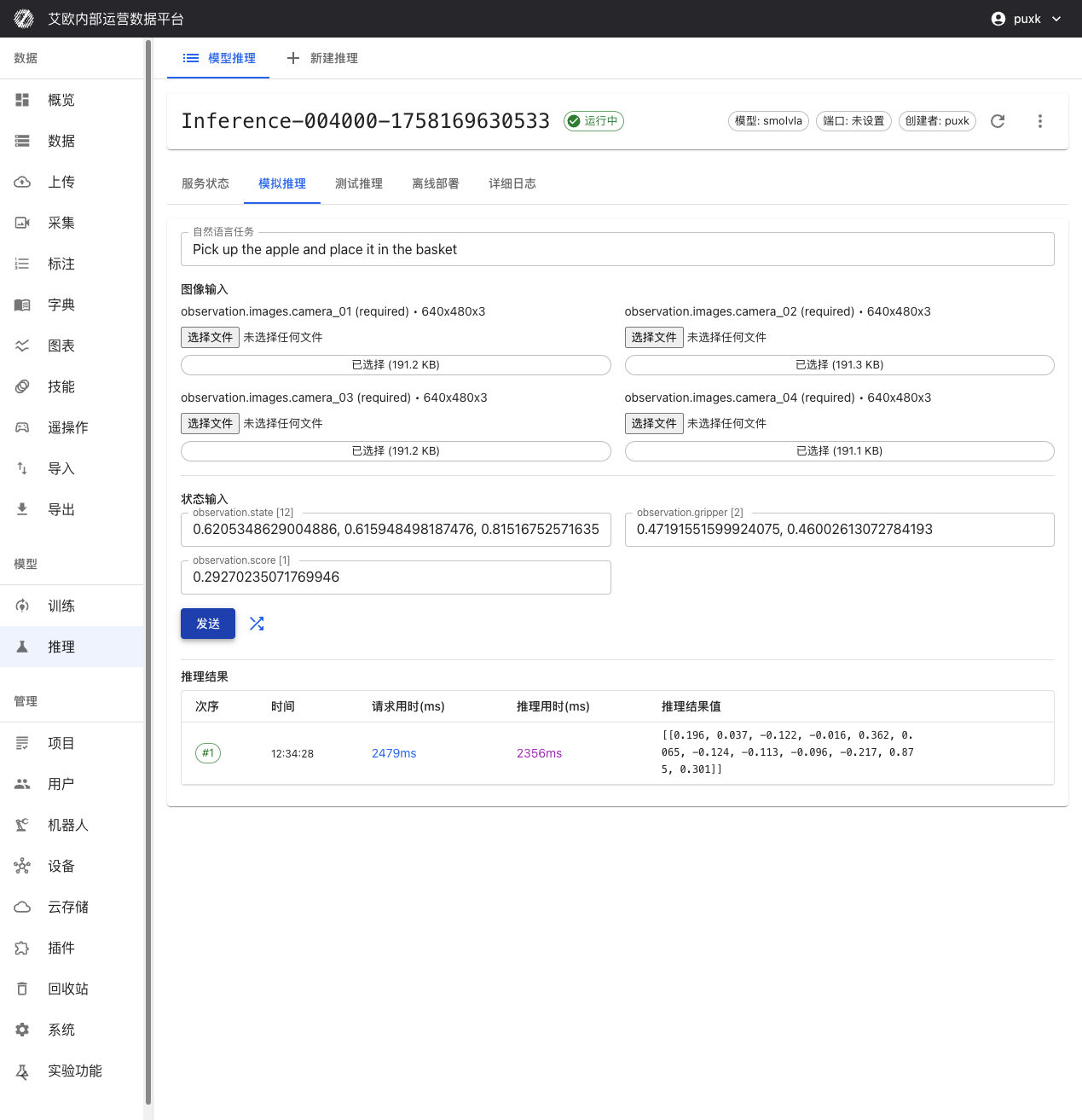
- 进入推理服务详情页,切换到"模拟推理"标签页
- 输入自然语言任务指令,如"Pick up the apple and place it in the basket"
- 点击"随机填充"自动生成测试数据,或手动输入数据
- 点击"发送"按钮,立即获得模型推理结果
性能指标:
- 请求用时:从发送请求到收到响应的总时间(包括网络传输)
- 推理用时:模型实际推理计算时间
- 数据传输时间:数据上传和下载的时间
这些指标帮助你评估模型性能和系统延迟。
MCAP 文件测试
什么时候使用?
- 评估模型在真实场景下的表现
- 对比推理结果与专家演示的差异
- 验证模型在完整动作序列上的效果
- 选择最佳模型检查点
如何使用?
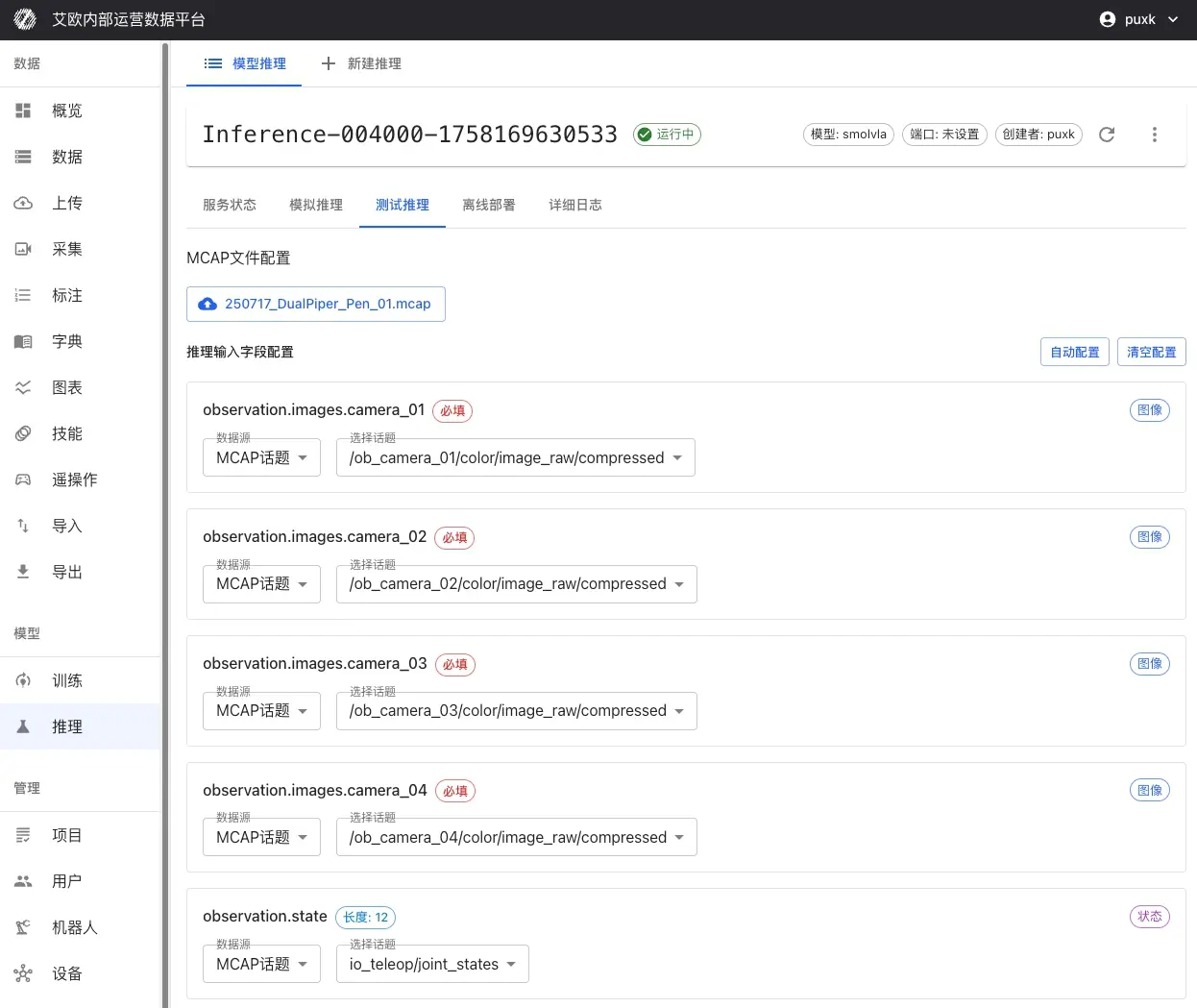
- 进入推理服务详情页,切换到"测试推理"标签页
- 选择 MCAP 文件:
- 从平台数据集直接选择
- 或本地上传 MCAP 文件
- 配置输入映射:
- 选择 MCAP 中的哪些相机话题映射到模型输入
- 配置关节状态、夹爪状态等数据的映射
- 为整个序列设置自然语言任务描述
- 设置推理范围:
- 选择推理的起始帧和结束帧
- 可以设置跳过某些帧以提高推理速度
- 开始推理:点击"开始推理",系统会对完整序列进行连续推理
效果对比分析:
推理完成后,系统会提供:
- 动作对比:对比推理动作与专家演示动作的差异
- 轨迹可视化:可视化预测轨迹与真实轨迹
- 误差统计:计算动作误差、位置误差等统计指标
- 性能评估:评估模型在真实数据上的表现
💡 建议:使用与训练数据相似场景的 MCAP 文件进行测试,关注动作误差和轨迹一致性。
离线边缘部署
什么时候需要离线部署?
- 生产环境中的实时机器人控制
- 网络不稳定或受限的环境
- 对延迟要求极高的应用场景
- 需要数据本地化的安全敏感场景
部署步骤:
-
环境准备:
- 在机器人控制器上安装 Docker 和 nvidia-docker2(如使用 GPU)
- 确保有足够的存储空间下载 Docker 镜像和模型文件
-
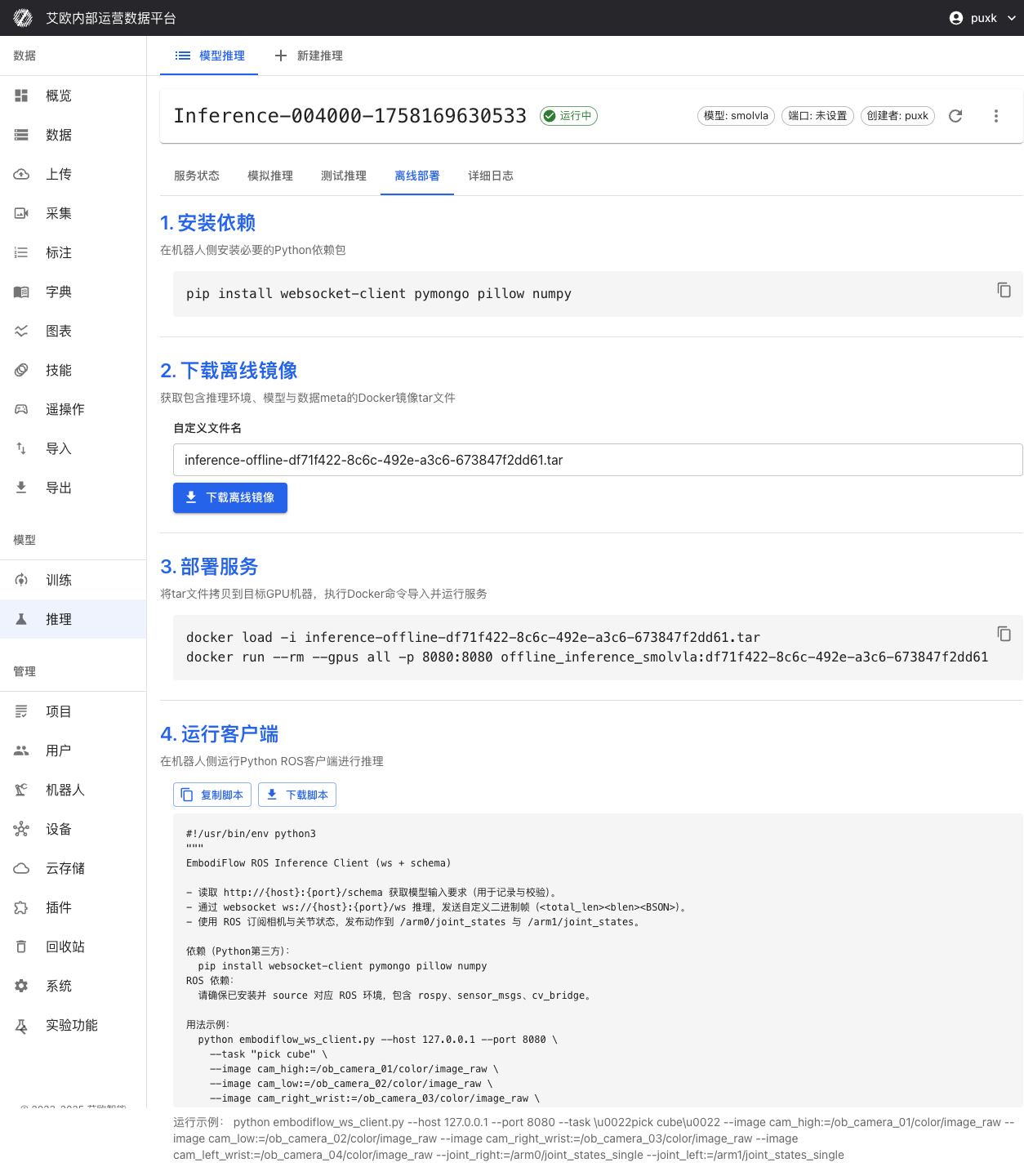
下载部署包:
- 在推理服务详情页切换到"离线部署"标签页
- 下载包含推理环境、模型权重和配置的完整 Docker 镜像
- 下载模型权重文件和配置文件
-
启动服务:
- 使用提供的 Docker 命令在本地启动推理服务
- 支持 GPU 加速(如果硬件支持)
- 自动配置端口和网络
-
客户端连接:
- 运行平台提供的 ROS 客户端脚本
- 建立与推理服务的实时通信(WebSocket + BSON 协议)
- 订阅传感器话题,发布关节控制指令
-
验证测试:
- 运行测试脚本验证服务是否正常
- 检查推理延迟和准确性
- 确认 ROS 话题的订阅和发布正常
离线部署优势:
- 低延迟:推理在机器人本地执行,完全消除网络延迟
- 离线可用:不依赖外部网络连接,确保离线环境可用
- 数据安全:数据不离开机器人本地,满足数据安全要求
- 实时控制:支持高频率推理(2-10Hz),满足实时控制需求
服务管理
如何查看服务状态?
服务信息:
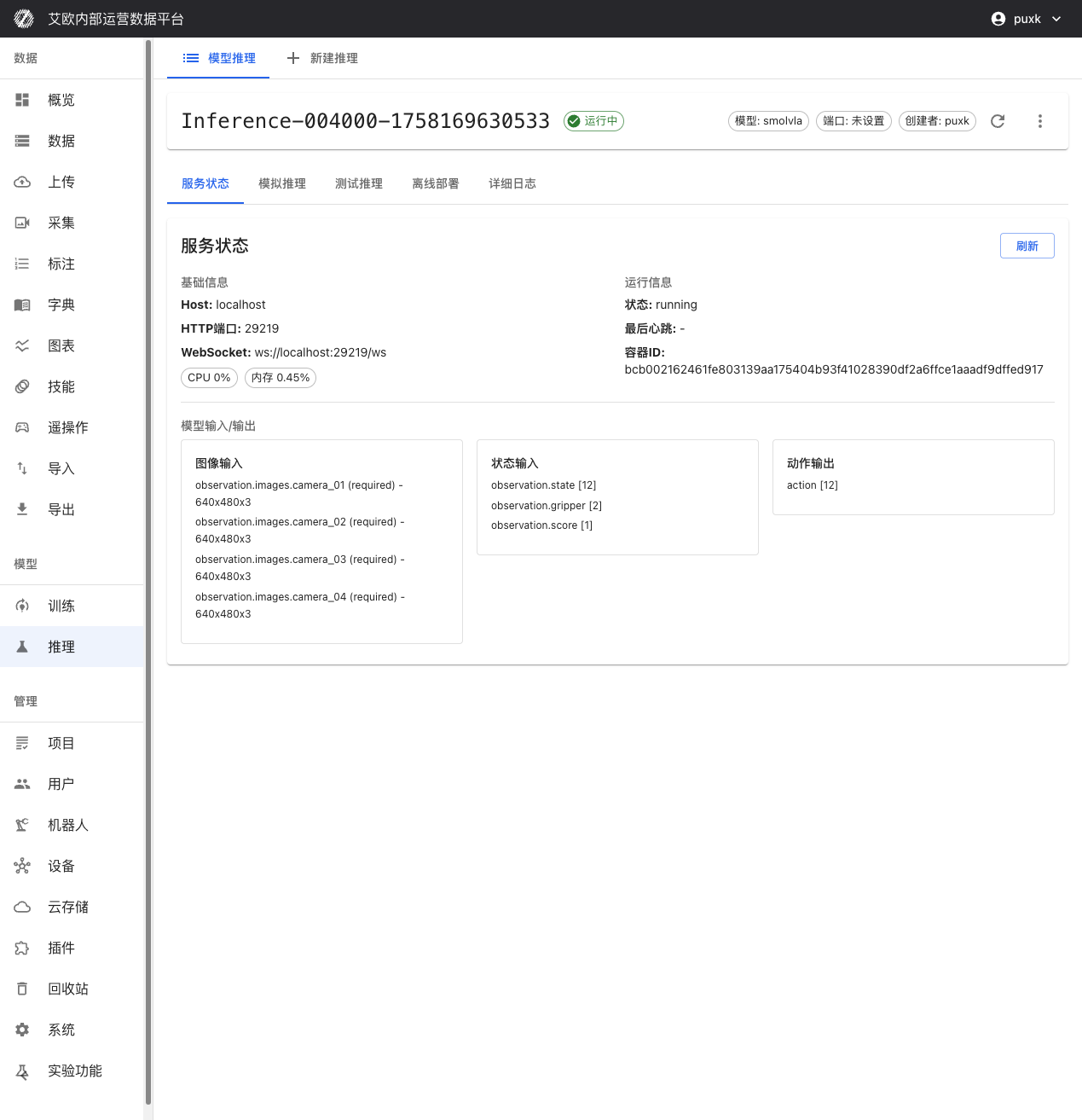
在推理服务详情页可以查看:
- Host 地址和端口:推理 API 的 HTTP 和 WebSocket 访问地址
- 服务状态:实时显示服务运行状态(运行中、已停止、错误等)
- 容器信息:Docker 容器 ID 和运行状态
- 创建时间:服务创建和最后更新时间
资源监控:
- CPU 使用率:实时显示 CPU 占用情况
- 内存使用:显示内存占用和峰值
- GPU 使用率:如果使用 GPU,显示 GPU 利用率和显存占用
- 网络 IO:显示网络流量统计
如何控制服务?
服务控制:
- 启动/停止:可以随时启动或停止推理服务
- 重启服务:重启服务以应用配置更改
- 删除服务:删除不需要的推理服务,释放资源
💡 建议:部署后建议等待 20-30 秒确保服务完全启动。长时间不使用的服务可以停止以释放资源。
模型输入输出规格
推理服务具备智能适配能力,可自动识别并适应不同模型的输入输出要求:
输入:
- 图像输入:智能适配相机数量(1 个或多个视角)和分辨率(自动缩放)
- 状态输入:observation.state [12]、observation.gripper [2]、observation.score [1]
输出:
- 动作输出:action [12] 机器人关节控制指令
系统会自动处理数据格式转换,你只需要按照模型要求提供数据即可。
推理配额管理
什么是推理配额?
推理配额用于控制资源使用,确保系统资源合理分配。
配额类型:
- 用户配额:每个用户有独立的推理配额限制
- 全局配额:系统级别的总配额限制(管理员配置)
- 配额统计:实时显示已使用配额和剩余配额
配额显示:
- 推理页面显示当前用户的配额使用情况
- 显示已使用数量和总配额限制
- 超出配额时无法创建新的推理服务
配额管理(管理员):
管理员可以:
- 查看所有用户的推理配额使用情况
- 配置全局推理配额限制
- 调整单个用户的配额
常见问题
如何选择合适的模型?
选择建议:
- 使用微调模型:首次部署建议使用微调模型,确保模型与训练数据匹配
- 快速测试:如果需要快速测试,可以使用预训练模型
- 自定义模型:自定义模型需要确保格式兼容和配置正确
推理服务启动失败怎么办?
可能原因:
- GPU 资源不足:检查 GPU 是否被其他服务占用
- 模型文件错误:检查模型文件是否完整和格式正确
- 配置错误:检查推理参数配置是否合理
- 容器启动失败:查看详细日志了解具体错误
解决方法:
- 查看服务日志,了解失败原因
- 根据错误信息修复问题
- 重新部署服务
如何提高推理速度?
优化建议:
- 使用 GPU:GPU 推理比 CPU 快很多
- 降低精度:使用 bfloat16 可以提升速度,但可能略微降低精度
- 调整批次大小:根据实际情况调整批次大小
- 使用离线部署:本地推理可以消除网络延迟
如何验证推理结果?
验证方法:
- 模拟推理:使用随机数据快速验证服务是否正常
- MCAP 测试:使用真实数据验证模型效果
- 对比分析:对比推理结果与专家演示的差异
- 实际测试:在真实机器人上测试推理效果
相关功能
完成推理服务部署后,你可能还需要: