モデル訓練
ロボット学習モデルの訓練には通常、複数のステップが必要です:データ処理、環境設定、訓練スクリプトの記述、訓練プロセスの監視など。非技術者にとって、このプロセスは複雑でエラーが発生しやすいです。
プラットフォームは製品化された訓練プロセスを提供します。コード記述は不要で、Webインターフェースを通じてデータ準備からモデルデプロイまでの完全な操作を完了できます。データを選択し、モデルを選択し、パラメータを設定し、訓練を開始するだけです。
クイックスタート:3ステップで訓練を開始
ステップ1:訓練データを準備
訓練データは複数のソースから取得できます:
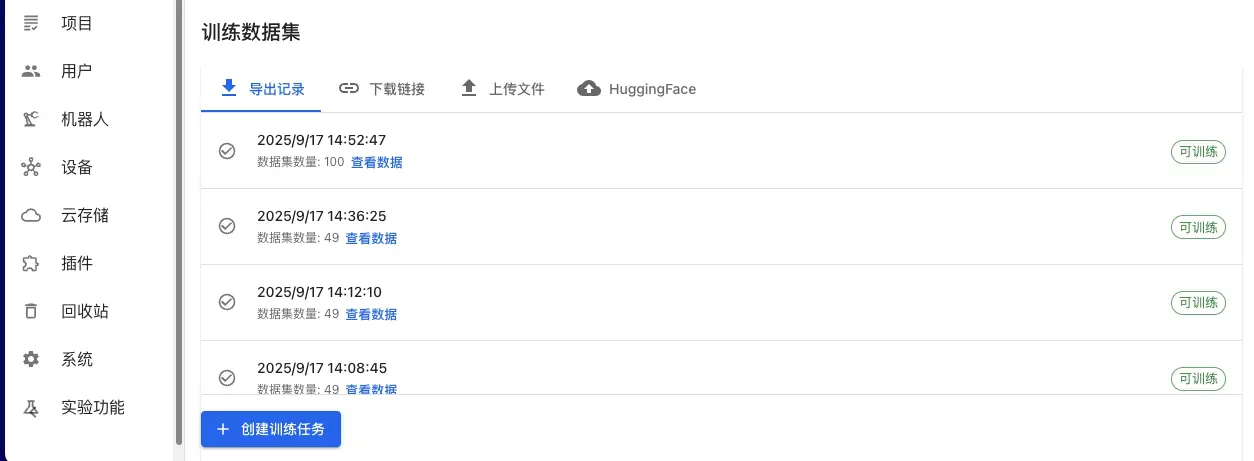
プラットフォームエクスポートデータ(推奨):
- データエクスポートページで、アノテーション済みデータセットを選択
- LeRobotまたはHDF5形式を選択してエクスポート
- エクスポート完了後、訓練ページで「プラットフォームエクスポートデータ」を選択
- エクスポート履歴から対応するエクスポート記録を選択
その他のデータソース:
- 外部データセット:URLリンクを通じて公開データセットをインポート
- ローカルデータアップロード:HDF5、LeRobotなどの標準形式をサポート
- HuggingFaceデータセット:HuggingFace Hubから直接公開データを取得
ステップ2:モデルとコンピューティングリソースを選択
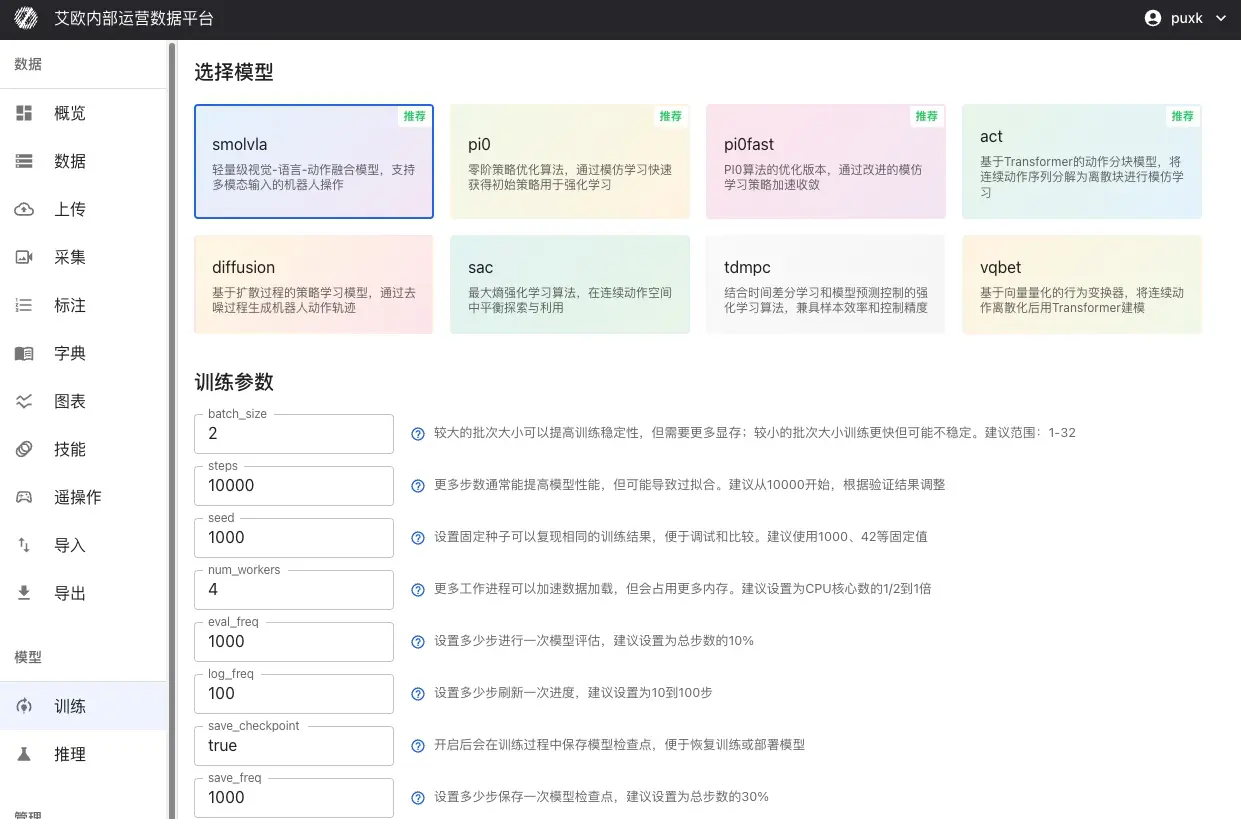
モデルタイプを選択:
タスク要件に基づい�て適切なモデルを選択:
| タスクタイプ | 推奨モデル | 説明 |
|---|---|---|
| 自然言語指示を理解 | SmolVLA、OpenVLA、Pi0 | ロボットが「机を整理してください」などの指示を理解し、実行可能 |
| エキスパートデモを模倣 | ACT、Pi0、Pi0.5 | エキスパートデモから学習して操作スキルを習得 |
| 複雑な操作シーケンス | Diffusion Policy | 組み立て、料理など精密制御が必要なタスクを学習 |
| 動的環境適応 | SAC、TDMPC | 動的環境で最適な制御戦略を学習 |
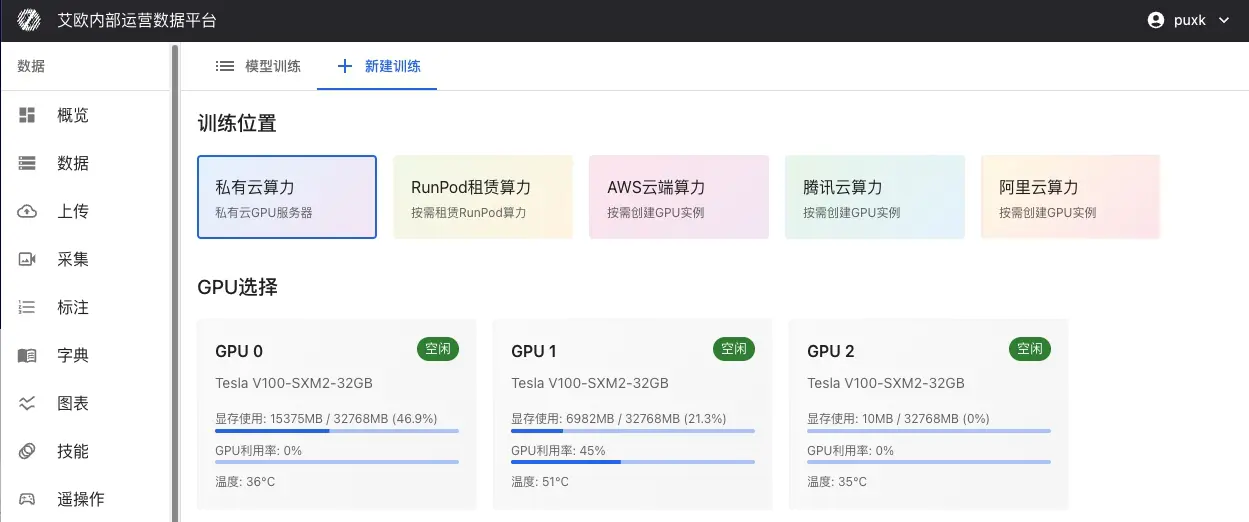
コンピューティングリソースを選択:
-
ローカルGPU:ローカルデータセンターのGPUサーバーを使用
- マルチGPU並列訓練をサポート
- GPU状態のリアルタイム表示(メモリ使用率、温度、利用率)
- 大規模データセットと長時間訓練に適している
-
パブリッククラウドリソース:クラウドプロバイダーからオンデマンドでコンピューティングパワーをレンタル
- RunPod、AWS EC2/SageMaker、Tencent Cloud、Alibaba Cloudなど
- 実際の訓練時間に応じて課金
- 一時的な訓練タスクやリソース拡張ニーズに適している
ステップ3:パラメータを設定して訓練を開始
基本パラメータ:
- batch_size(バッチサイズ):推奨範囲1-32、GPUメモリに基づいて調整
- steps(訓練ステップ数):10000から開始することを推奨、検証結果に基づいて調整
- eval_freq(評価頻度):評価間のステップ数、総ステップ数の10%を推奨
学習率設定:
- optimizer_lr(学習率):推奨範囲1e-4から1e-5
- 大きすぎると訓練が不安定になり、小さすぎると収束が遅い
- 事前訓練モデルのファインチューニングでは、学習率を下げることを推奨(1e-5)
モデル固有パラメータ:
異なるモデルには独自の特定パラメータがあります。システムは選択されたモデルに基づいて対応するパラメータ設定項目を表示します。
設定完了後、「訓練を開始」をクリックします。
サポートされているモデルタイプ
プラットフォームはロボティクス分野の主流学習モデルをサポートし、複数の技術アプローチをカバーします:
ビジョン-言語-アクションモデル
SmolVLA:自然言語指示、視覚知覚、ロボットアクションのエンドツーエンド学習を実行する軽量マルチモーダルモデル。リソース制約のあるシナリオ、リアルタイム応答、リソースフレンドリーに適している。
OpenVLA:大規模事前訓練ビジョン-言語-アクションモデル、複雑なシーン理解と操作計画をサポート。強力な理解能力が必要なタスクに適している。
GR00T:マルチモーダルGR00Tポリシー、ビジョンと言語の共同計画をサポートし、強力な汎用操作能力を持つ。
模倣学習モデル
ACT(Action Chunking Transformer):Transformerアーキテクチャに基づくアクションチャンキングモデル、連続アクションシーケンスを離散チャンクに分解して学習。エキスパートデモデータがあるタスクに適している。
Pi0:Physical IntelligenceのオープンソースフラグシップVLAモデル、OpenPIフレームワークを通じて��ファインチューニングされ、極めて強力な汎用操作能力を持つ。詳細はPi0ファインチューニングガイドを参照。
Pi0.5:より優れた汎化とオープンワールド適応性を持つ強化Piモデル、より複雑な操作タスクをサポート。
ポリシー学習モデル
Diffusion Policy:拡散プロセスに基づくポリシー学習、ノイズ除去プロセスを通じて連続ロボットアクション軌跡を生成。生成されたアクションは滑らかで自然。
VQBET:Vector Quantized Behavior Transformer、連続アクション空間を離散化してからTransformerでモデル化。
強化学習モデル
SAC(Soft Actor-Critic):最大エントロピー強化学習アルゴリズム、連続アクション空間で探索と利用のバランスを取る。
TDMPC:Temporal Difference Model Predictive Control、モデルベース計画とモデルフリー学習の利点を組み合わせる。
報酬学習モデル
Reward Classifier:報酬関数学習モデル、アノテーションデータから報酬信号を学習し、強化学習訓練に使用。
訓練ワークフロー
プラットフォームはデータ収集からモデルデプロイまでの完全なプロセスをカバーします:
高度な使用
訓練パラメータを設定するには?
一般的な訓練パラメータ:
-
batch_size(バッチサイズ):各訓練イテレーションで使用されるサンプル数を制御
- 推奨範囲:1-32
- 大きなバッチは訓練の安定性を向上させるが、より多くのメモリが必要
- GPUメモリサイズに基づいて調整し、メモリオーバーフローを回避
-
steps(訓練ステップ数):モデルの総訓練ステップ数
- 10000から開始することを推奨
- 検証結果に基づいて調整し、過学習または未学習を回避
-
seed(ランダムシー��ド):訓練結果の再現性を確保
- 1000、42などの固定値を使用することを推奨
-
eval_freq(評価頻度):モデル評価間のステップ数
- 総ステップ数の10%を推奨
- 評価が頻繁すぎると訓練速度に影響
-
save_freq(保存頻度):チェックポイント保存間のステップ数
- 総ステップ数の30%を推奨
- 保存が頻繁すぎるとストレージスペースを占有
オプティマイザーパラメータ:
-
optimizer_lr(学習率):パラメータ更新の大きさを制御
- 推奨範囲:1e-4から1e-5
- 大きすぎると訓練が不安定になり、小さすぎると収束が遅い
- 事前訓練モデルのファインチューニングでは、学習率を下げることを推奨(1e-5)
-
optimizer_weight_decay(重み減衰):過学習を防ぐ正則化パラメータ
- 推奨範囲:0.0から0.01
-
optimizer_grad_clip_norm(勾配クリッピング閾値):勾配爆発を防ぐ
- 1.0に設定することを推奨
モデル固有パラメータ:
異なるモデルは独自の特定パラメータをサポートします:
ACTモデル:
chunk_size(アクションチャンクサイズ):一度に予測されるアクションシーケンスの長さ、推奨範囲10-50n_action_steps(実行ステップ数):実際に実行されるアクションステップ数、通常chunk_sizeと等しいvision_backbone(ビジョンバックボーン):オプションresnet18/34/50/101/152
Diffusion Policyモデル:
horizon(予測時間スパン):拡散モデルのアクション予測長、推奨16num_inference_steps(推論ステップ数):サンプリングステップ数、推奨10
SmolVLA/OpenVLAモデル:
max_input_seq_len(最大入力シーケンス長):入力トークン数を制限、推奨256-512freeze_lm_head(言語モデルヘッドを凍結):ファインチューニング中に有効化することを推奨freeze_vision_encoder(ビジョンエンコーダーを凍結):ファインチューニング中に有効化することを推奨
💡 パラメータ設定推奨事項:
- 最初の訓練では、訓練が正常に進行することを確保するためにデフォルトパラメータを使用することを推奨
- GPUメモリサイズに基づいてbatch_sizeを調整
- 事前訓練モデルのファインチューニングでは、学習率を下げ、一部のレイヤーを凍結することを推奨
- 定期的に訓練ログを確認し、損失曲線に基づいて学習率を調整
訓練プロセスを監視するには?
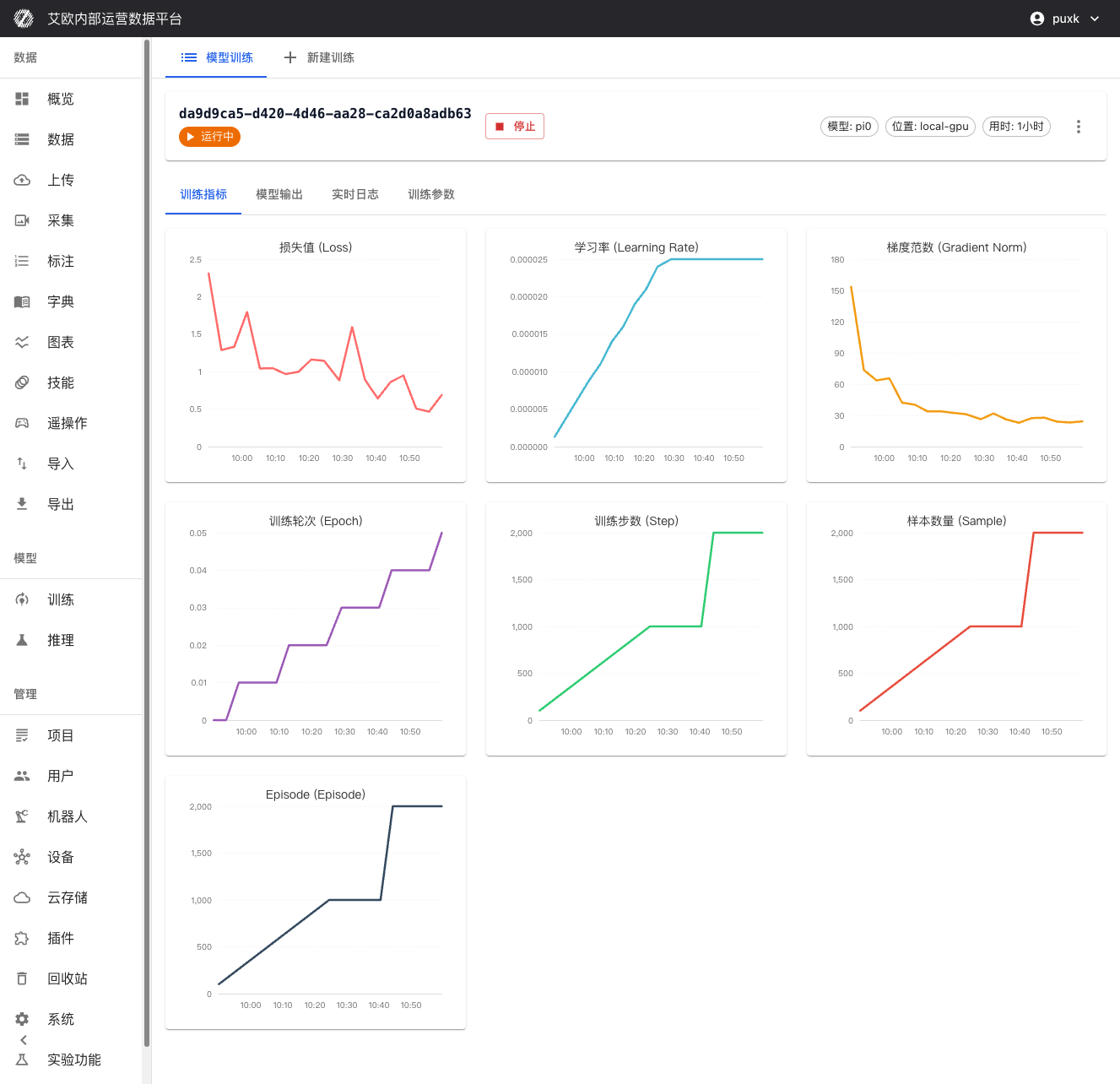
訓練指標の可視化:
訓練詳細ページでリアルタイムに以下を確認できます:
- 損失関数曲線:訓�練損失と検証損失のリアルタイム表示、モデルの収束を判断するのに便利
- 検証精度指標:検証セットでのモデルパフォーマンスを表示
- 学習率の変化:学習率スケジューリング戦略の実行を可視化
- 訓練進捗:完了ステップ数、総ステップ数、推定残り時間などの情報を表示
リソース監視:
- GPU利用率とメモリ使用率のリアルタイム監視
- CPUとメモリ使用率の追跡
- ネットワークIOとディスクIOの監視(該当する場合)
システムログ:
- 詳細な訓練ログ記録、各訓練ステップの詳細情報を含む
- エラーと警告のリアルタイム表示、迅速な問題特定
- ログのリアルタイムストリーミングをサポート、いつでも最新の訓練状態を確認可能
訓練タスクを管理するには?
プロセス制御:
- 訓練を一時停止:訓練タスクを一時的に一時停止し、現在の進捗を保持
- 訓練を再開:一時停止ポイントから再開し、シームレスに継続
- 訓練を停止:訓練�タスクを安全に停止し、現在のチェックポイントを保存
- 訓練を再起動:訓練タスクを再起動
チェックポイント管理:
訓練中および訓練後、保存されたすべてのチェックポイントが訓練詳細ページに表示されます:
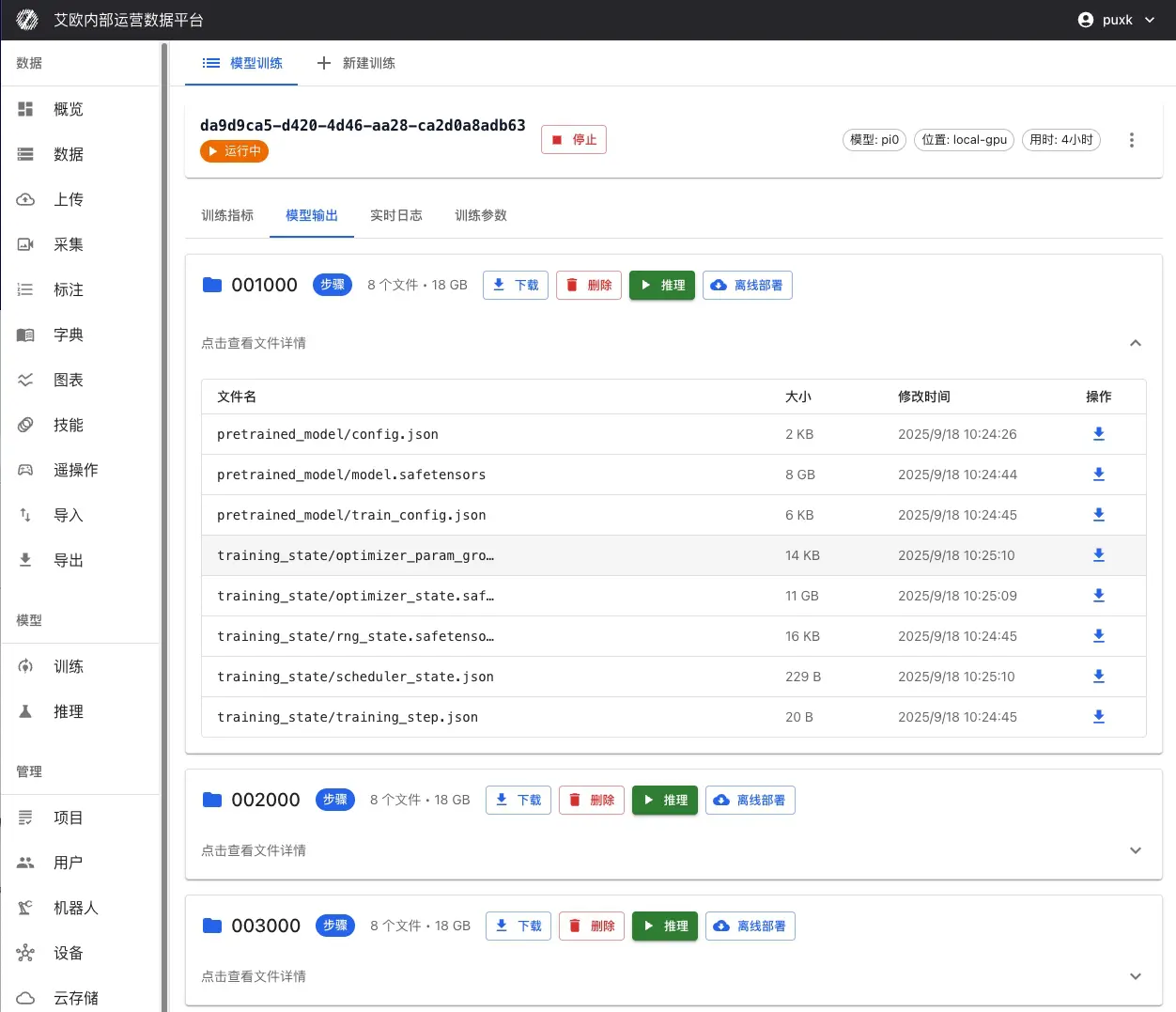
チェックポイント情報:
- チェックポイント名:自動生成またはカスタムチェックポイント名(例:「step_1000」、「last」など)
- 訓練ステップ数:このチェックポイントに対応する訓練ステップ数
- 保存時間:チェックポイントが保存されたタイムスタンプ
- ファイルサイズ:チェックポイントファイルのサイズ
- パフォーマンス指標:検証セットでのこのチェックポイントのパフォーマンス
チェックポイント操作:
- 詳細を確認:チェックポイントの詳細情報と評価結果を確認
- チェックポイントをダウンロード:チェックポイントファイルをローカルにダウンロードし、オフラインデプロイまたはさらなる分析に使用
- ベストとしてマーク:最高のパフォーマンスを持つチェックポイントをベストモデルとしてマーク
- 推論をデプロイ:チェックポイントから直接ワンクリックで推論サービスとしてデプロイ
チェックポイントの注意事項:
- last:最後に保存されたチェックポイント、通常は最新のモデル状態
- best:検証セットで最高のパフォーマンスを持つチェックポイント、通常は本番デプロイに使用
- step_xxx:訓練ステップで保存されたチェックポイント、訓練プロセスを分析するために使用可能
タスク操作:
- パラメータ調整:訓練中に一部の訓練パラメータを確認および調整可能(注意して使用)
- タスクコピー:成功した訓練設定に基づいて新しいタスクを迅速に作成し、最良の設定を再利用
- タスク削除:不要な訓練タスクを削除してストレージスペースを解放
失敗した訓練から回復するには?
訓練タスクが失敗した場合:
- エラー情報を確認:訓練詳細ページで詳細なエラーログを確認
- 失��敗理由を分析:一般的な理由には以下が含まれます:
- メモリ不足:batch_sizeを下げるか、より大きなGPUを使用
- データ形式エラー:データ形式が要件を満たしているかどうかを確認
- パラメータ設定エラー:パラメータ設定が合理的かどうかを確認
- パラメータを修正:訓練詳細ページで「パラメータを修正」をクリックし、設定を調整してから再訓練
- チェックポイントから再開:以前にチェックポイントが保存されていた場合、チェックポイントから訓練を継続可能
💡 推奨:訓練中断によるデータ損失を避けるために、定期的にチェックポイントを保存してください。
訓練クォータ管理
訓練クォータとは?
訓練クォータは、リソース使用を制御し、システムリソースの合理的な配分を確保するために使用されます。
クォータタイプ:
- ユーザークォータ:各ユーザーは独立した訓練クォータ制限を持つ
- グローバルクォータ:システムレベルの総クォータ制限(管理者が設定)
- クォータ統計:使用済みクォータと残りクォータのリアルタイム表示
クォータ表示:
- 訓練ページに現在のユーザーのクォータ使用状況を表示
- 使用済み数と総クォータ制限を表示
- クォータを超過すると新しい訓練タスクを作成できない
クォータ管理(管理者):
管理者は以下を実行できます:
- すべてのユーザーの訓練クォータ使用状況を確認
- グローバル訓練クォータ制限を設定
- 個別ユーザークォータを調整
よくある質問
適切なモデルを選択するには?
選択推奨事項:
- タスクタイプを決定:指示理解、模倣学習、または強化学習か?
- モデル説明を確認:各モデルには詳細な説明があり、適用シナリオを理解
- アプリケーションケースを参照:モデルアプリケーションケースを確認し、タスクに最も近いモデルを選択
- 小規模から開始:まず小規模データセットでテストし、大規模訓練の前にモデル効果を確認
訓練にはどのくらい時間がかかるか?
時間見積もり:
訓練時間は以下に依存します:
- データ量:データが多いほど訓練時間が長い
- モデルの複雑さ:複雑なモデルはより長い時間が必要
- コンピューティングリソース:より良いGPUパフォーマンスはより高速な訓練を意味する
- 訓練ステップ数:より多くのステップはより長い訓練時間を意味する
一般的なケース:
- 小規模データセット(1000未満):1-3時間
- 中規模データセット(1000-10000):3-12時間
- 大規模データセット(10000以上):12時間以上
最適化推奨事項:
- マルチGPU並列訓練を使用すると、時間を大幅に短縮可能
- 適切にbatch_sizeを下げると、単一ステップの速度を向上可能
- より強力なGPUを使用すると、訓練速度を向上可能
訓練が正常かどうかを判断するには?
正常な訓練指標:
- 損失が減少:訓練損失は徐々に減少する必要がある
- 検証指標が改善:検証セットでのパフォーマンスは徐々に改善する必要がある
- リソースが安定:GPU利用率は安定している必要があり、頻繁に変動しない
- エラーログがない:ログに大量のエラー情報があってはならない
異常な状況:
- 損失が減少しない:学習率が大きすぎるか小さすぎる可能性があり、調整が必要
- 損失が振動する:batch_sizeが小さすぎる可能性があり、増やす必要がある
- メモリオーバーフロー:batch_sizeを下げるか、より大きなGPUを使用する必要がある
- 訓練が停止:データローディングが正常かどうか、ネットワークが安定しているかどうかを確認
訓練が失敗した場合はどうすればよいか?
処理手順:
- エラーログを確認:訓練詳細ページで詳細なエラー情報を確認
- 失敗理由を分析:エラー情報に基づいて、データ問題、パラメータ問題、またはリソース問題かを判断
- 問題を修正:理由に基づいて対応措置を講じる
- 再訓練:修正後に新しい訓練タスクを作成
一般的なエラー:
- メモリ不足:batch_sizeを下げるか、より大きなGPUを使用
- データ形式エラー:データ形式が要件を満たしているかどうかを確認
- パラメータ設定エラー:パラメータ設定が合理的かどうかを確認
- ネットワーク問題:ネットワーク接続が安定しているかどうかを確認
関連機能
モデル訓練を完了した後、以下も必要になる場合があります:
- 推論サービス:訓練されたモデルを推論用にデプロイ
- データエクスポート:訓練データをエクスポート
- アクションリターゲティング:アクションを異なるロボットに適応